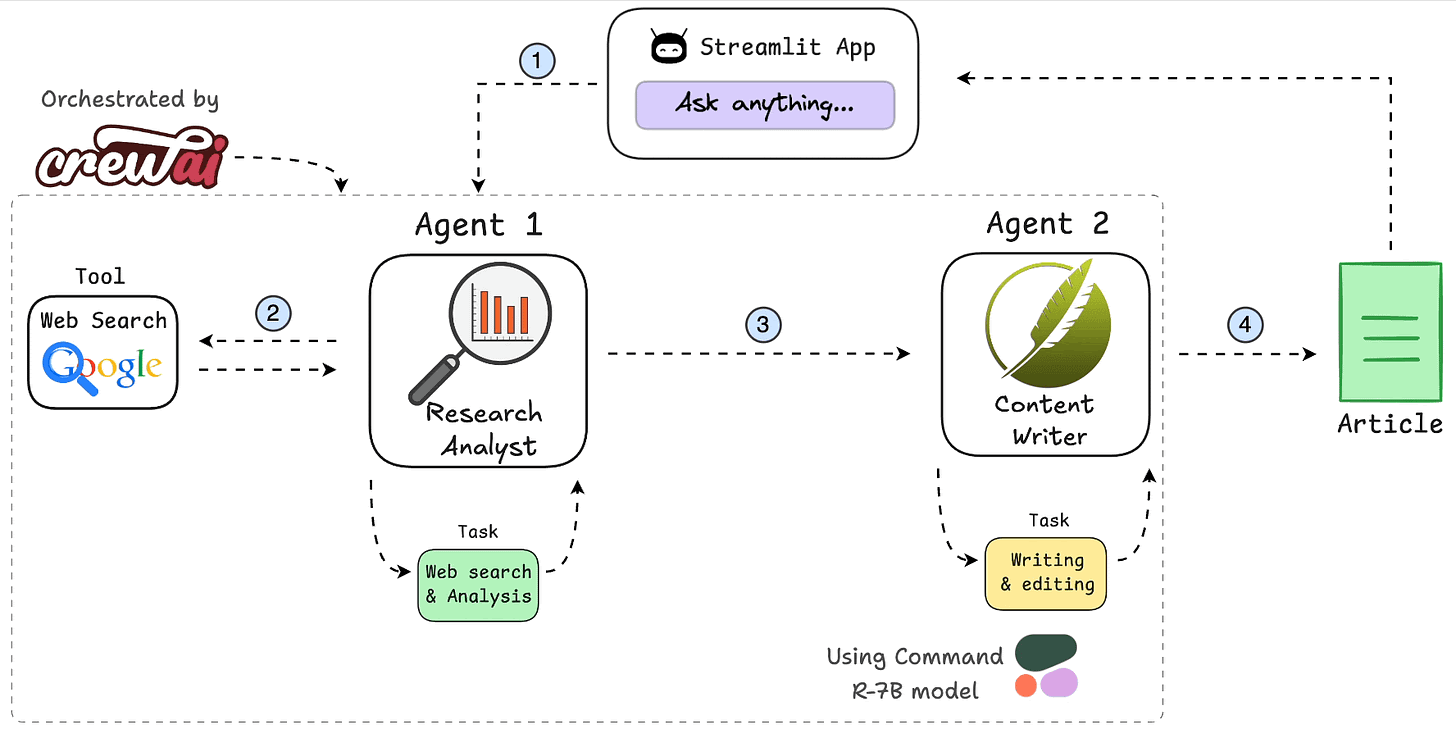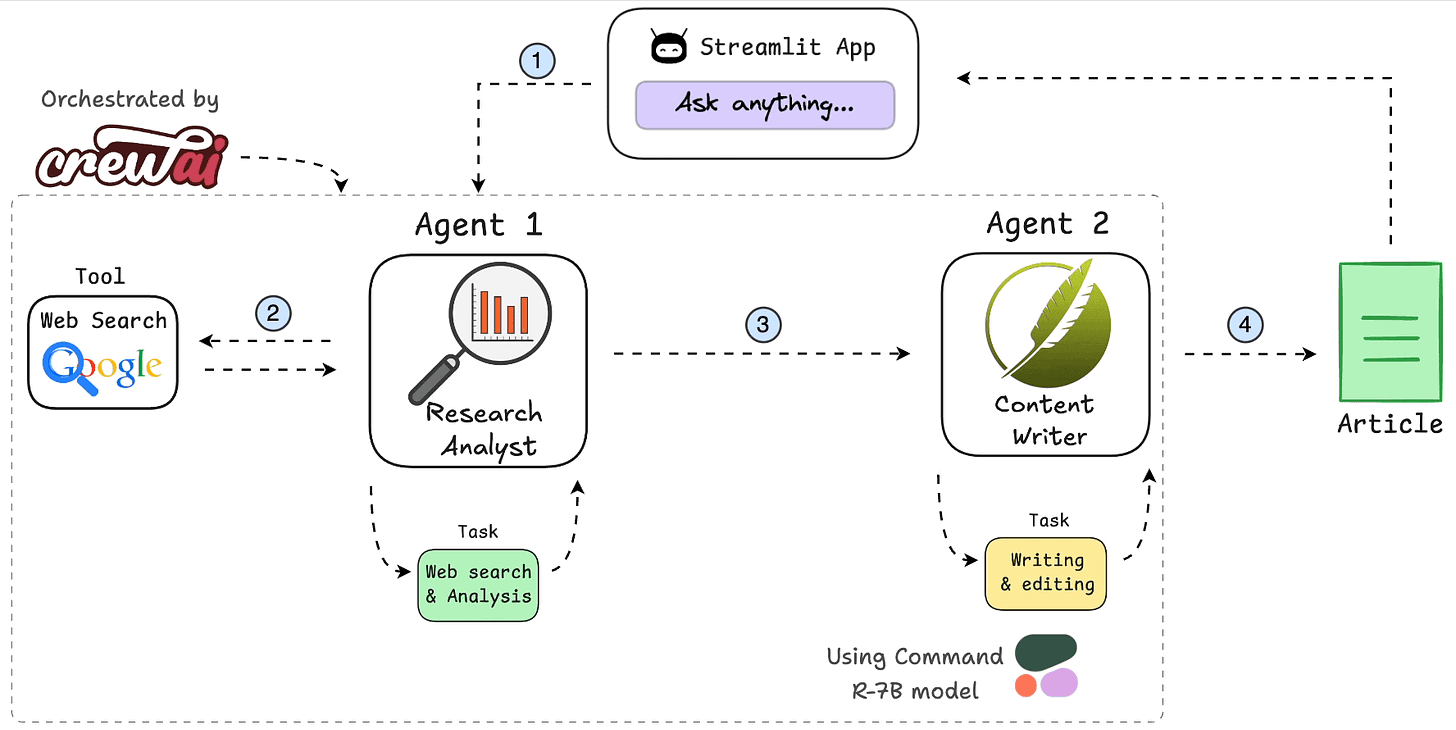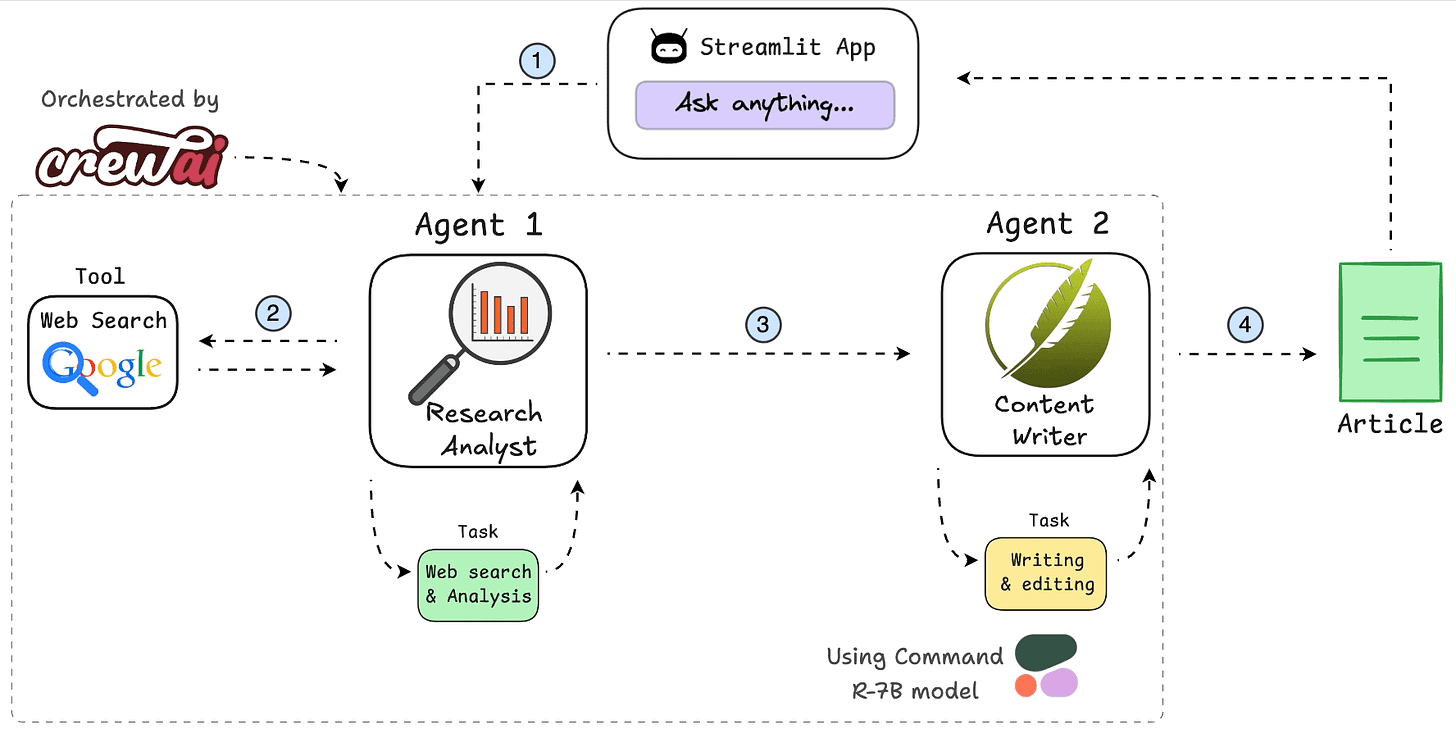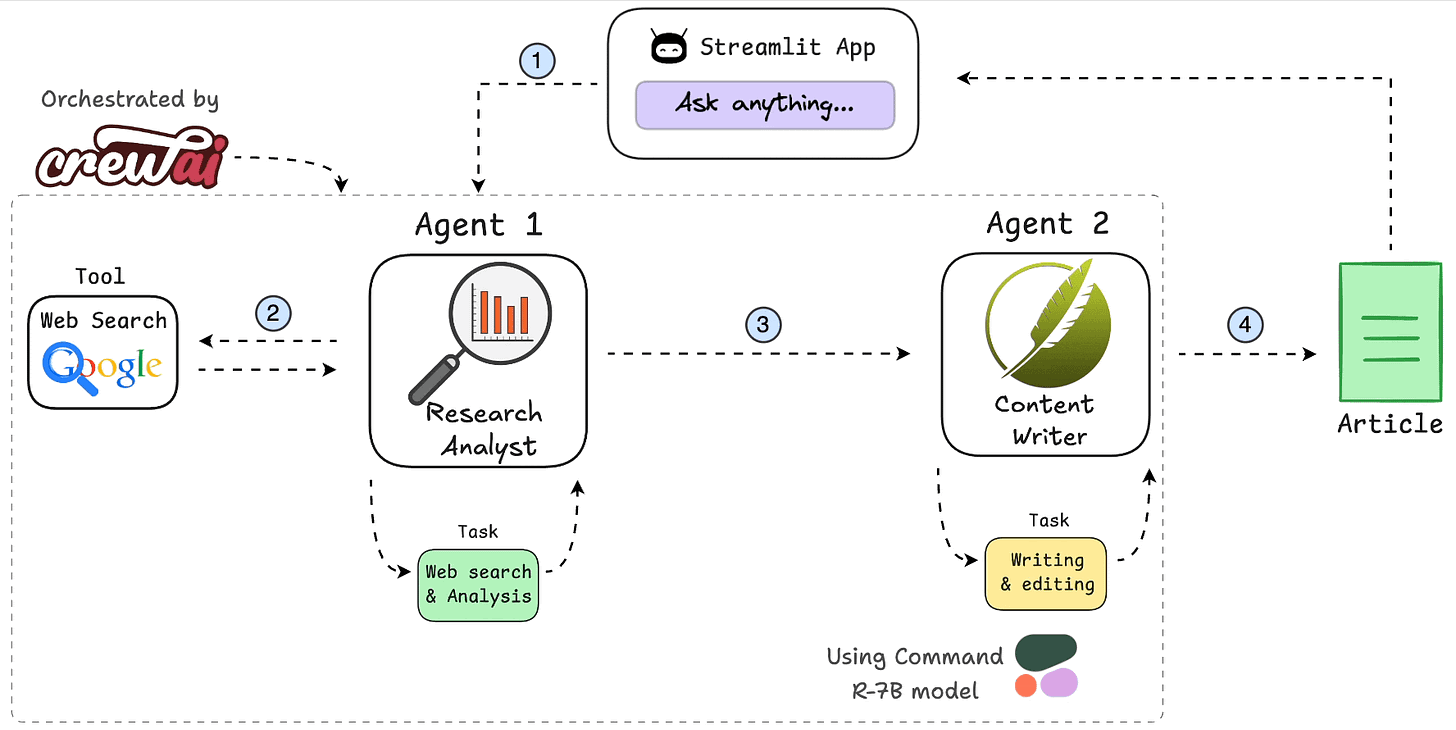
ZooKeeper简介
Apache ZooKeeper是一个开源的分布式协调服务,广泛用于分布式系统中以解决配置管理、命名服务、分布式同步和集群管理等问题。它提供了一种简单而强大的机制来实现这些功能,从而简化分布式应用程序的开发。Zookeeper是Google的Chubby一个开源的实现。

产生背景
Apache ZooKeeper的产生背景可以追溯到雅虎(Yahoo!)在构建和维护大规模分布式系统时所面临的一系列挑战。
随着互联网的快速发展,雅虎和其他大型互联网公司开始构建和维护大规模的分布式系统。这些系统需要处理海量数据和高并发请求,因此对可靠性和性能提出了极高的要求。在这样的背景下,分布式系统的设计和管理变得非常复杂,需要解决以下几个关键问题:
- 配置管理: 如何在多个节点之间一致地管理和分发配置信息?
- 命名服务: 如何为分布式系统中的各个组件提供统一的命名和地址解析?
- 分布式锁: 如何在多个节点之间实现互斥访问,避免资源竞争?
- 领导选举: 如何在分布式系统中选举一个领导者,以协调和管理各个节点的工作?
- 集群管理: 如何监控和管理集群中节点的健康状态,确保系统的高可用性?
在ZooKeeper诞生之前,虽然有一些现有的解决方案和技术可以部分解决上述问题,但它们往往存在以下不足:
- 复杂性: 现有的解决方案通常较为复杂,需要大量的手工配置和管理。
- 一致性: 很多解决方案无法保证强一致性,导致数据不一致的问题。
- 可扩展性: 现有方案在大规模分布式系统中的可扩展性较差,难以应对快速增长的用户和数据量。
- 可靠性: 现有方案在节点故障时的恢复能力和可靠性不足。
为了克服这些不足,雅虎的研究团队决定开发一个新的分布式协调服务,这就是ZooKeeper。ZooKeeper的设计目标是提供一个简单、高效、可靠的分布式协调服务,以解决大规模分布式系统中的常见问题。具体来说,ZooKeeper的设计目标包括:
- 高可用性: 通过复制机制确保在节点故障时仍能继续提供服务。
- 一致性: 提供强一致性模型,确保在集群中的所有节点上数据的一致性。
- 简洁性: 提供简单的编程接口和数据模型,方便开发者使用。
- 快速性: 在读操作上提供高吞吐量和低延迟。
2008年,雅虎将ZooKeeper开源,并将其捐赠给Apache软件基金会。这一举措迅速吸引了广泛的社区支持和贡献,ZooKeeper成为了Apache的顶级项目。开源后,ZooKeeper不断得到改进和完善,成为许多分布式系统和框架(如Hadoop、Kafka、HBase等)的核心组件。
优缺点
Apache ZooKeeper是一个强大的分布式协调服务,广泛用于解决分布式系统中的各种协调问题。它具有许多优点,同时也有一些局限性。
优点
- 事件驱动: 支持监听机制,客户端可以注册监听器以接收数据变化的通知,这对于实现实时响应非常有用。
- 丰富的功能: 支持分布式锁、命名服务、配置管理、领导选举和集群管理等多种功能。
缺点
- 写性能限制: 由于强一致性要求,ZooKeeper的写操作需要在集群中进行同步,因此写性能可能受到影响,尤其是在大规模集群中。
- 复杂的运维: ZooKeeper需要专业的运维和监控,尤其是在大规模集群环境下,配置和管理可能比较复杂。
- 数据存储限制: ZooKeeper适合存储小数据(通常不超过几MB),对于大数据存储并不适合。
- 依赖于网络延迟: ZooKeeper的性能和可靠性依赖于网络延迟和稳定性,在高延迟或不稳定的网络环境中可能表现不佳。
Apache ZooKeeper是一个功能强大且灵活的分布式协调服务,适用于多种分布式系统场景。它的高可用性、一致性和简单性使其成为解决配置管理、命名服务、分布式锁和集群管理等问题的理想选择。然而,在使用ZooKeeper时,需要考虑其写性能限制和数据存储限制,并确保良好的运维和网络环境。通过合理的架构设计和配置,ZooKeeper可以显著简化分布式系统的开发和管理。
ZooKeeper的架构
Apache ZooKeeper的架构设计旨在提供高可用性、一致性和快速的分布式协调服务。其核心架构采用了客户端-服务器模式,并通过复制和选举机制来实现高可用性和一致性。以下是ZooKeeper的架构详细说明:
架构组件
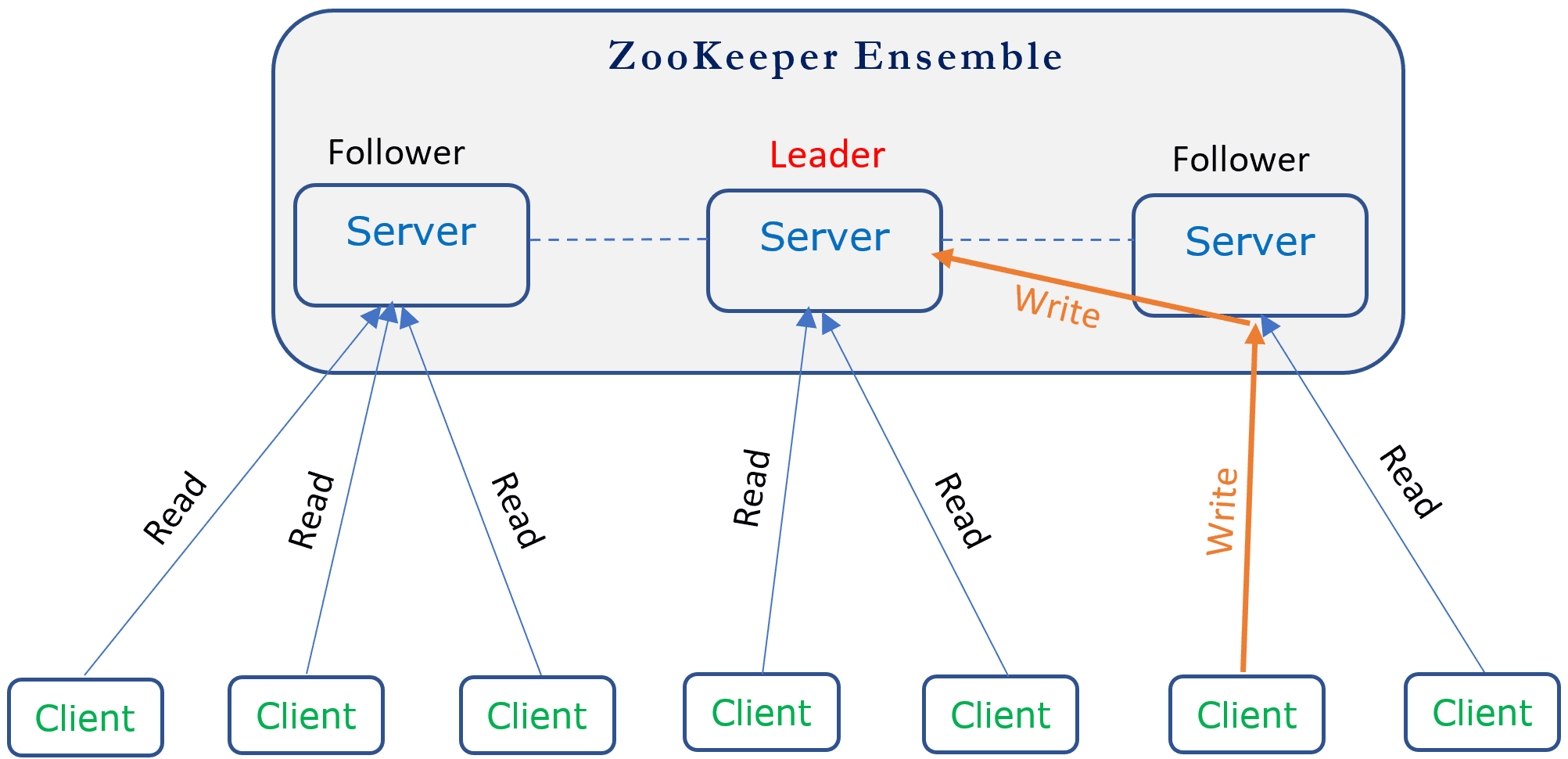
- ZooKeeper Ensemble(集群):
- ZooKeeper运行在一个集群中,通常由多个服务器节点组成,这些节点被称为ZooKeeper ensemble。推荐使用奇数个节点(如3、5、7),以便在发生故障时能够进行领导者选举。
- 集群中的节点分为两种角色:领导者(Leader)和追随者(Follower)。
- Leader(领导者):
- 负责处理所有写请求(事务请求),并将数据状态变更同步到其他追随者节点。
- 负责进行提议(Proposal)和提交(Commit)过程,以确保所有节点的数据一致性。
- 负责进行领导者选举和协调集群中的其他节点。
- Follower(追随者):
- 处理客户端的读请求。
- 将写请求转发给领导者。
- 参与选举过程,接收和应用来自领导者的提议和提交。
- Observer(观察者):
- 类似于追随者,但不参与选举和写请求的投票。
- 适用于需要扩展读请求吞吐量而不影响写性能的场景。
数据模型

- ZNode:
- ZooKeeper的数据结构是类似于文件系统的层次命名空间,称为ZNode。
- 每个ZNode可以存储少量数据(通常不超过几MB),并且可以有子节点。
- ZNode类型:
- 持久节点(Persistent ZNode): 一旦创建,除非显式删除,否则将一直存在。
- 临时节点(Ephemeral ZNode): 与客户端会话相关联,会话结束时自动删除。
- 有序节点(Sequential ZNode): 创建时分配一个唯一的递增序号。
工作机制
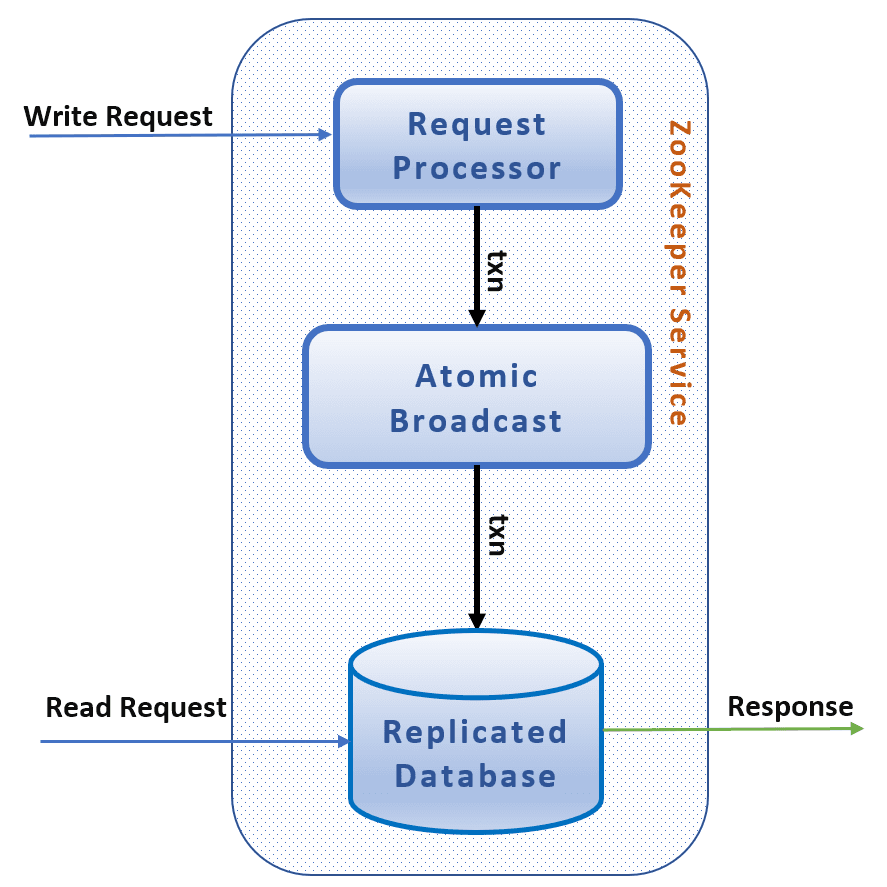
- 写请求处理:
- 所有写请求由领导者处理。领导者生成提议(Proposal),并将其广播给所有追随者。
追随者接受提议后,返回确认(Ack)给领导者。
- 当领导者收到超过半数的确认时,提交(Commit)该提议,并通知所有追随者应用变更。
- 读请求可以由任何追随者处理,提供高吞吐量和低延迟。
- 当领导者故障或集群启动时,ZooKeeper使用基于ZAB协议(ZooKeeper Atomic Broadcast)的选举算法来选举新的领导者。
- 选举过程确保在任何时刻只有一个活跃的领导者。
客户端交互
- 会话:
- 客户端与ZooKeeper集群之间通过会话进行交互,会话具有超时时间。
- 客户端可以通过会话创建、删除和监视ZNode。
- 监视器(Watch):
- 客户端可以在ZNode上设置监视器,以接收数据变更或节点状态变化的通知。
- 监视器是一次性的,触发后需要重新设置。
复制和一致性
- ZAB协议:
- ZooKeeper使用ZAB协议来实现数据的复制和一致性。
- 确保所有节点在写操作上的顺序一致性。
参考链接: