Apache Storm简介
Apache Storm是一个开源的、分布式的实时计算系统,旨在处理和分析大规模的数据流。它可以持续地接收数据,并在收到数据后立即进行处理,适用于需要低延迟的数据处理场景,如实时数据分析、在线机器学习、连续计算等。
Apache Storm的产生背景可以追溯到大数据处理需求的快速增长,尤其是在需要实时数据处理的场景中。以下是一些推动Storm产生的背景因素:
- 实时数据处理需求:
- 随着互联网和物联网的快速发展,各种应用和设备生成了大量的实时数据。这些数据需要在生成时立即进行处理和分析,以支持实时决策和操作。
- 传统的批处理系统(如Apache Hadoop)主要设计用于处理静态数据集,无法满足实时数据处理的需求。
- 大规模数据流处理:
- 许多行业,如金融、广告技术、社交媒体和电信,需要处理大规模的实时数据流。对于这些行业,能够实时分析和反应数据变化至关重要。
- 需要一个系统能够高效地处理这些数据流,同时提供低延迟和高吞吐量。
- 分布式计算需求:
- 单一服务器的计算能力有限,无法处理海量数据流。因此,需要一个能够在多个节点上分布式运行的系统,以便水平扩展处理能力。
- Storm的设计目标之一是提供一个简单而强大的分布式实时计算框架。
- 容错和高可用性:
- 实时数据处理系统必须具备容错能力,以应对节点故障和网络问题,确保系统的稳定性和可靠性。
- Storm提供了内置的容错机制,能够自动恢复失败的任务。
- 易用性和多语言支持:
- 开发者需要一个易于使用的实时处理框架,以便快速开发和部署应用。
- Storm支持多种编程语言,使得开发者能够使用自己熟悉的语言进行开发。
Apache Storm最初由Nathan Marz在BackType开发,后来被Twitter收购并在内部广泛使用。2011年,Twitter将Storm开源,之后成为Apache软件基金会的顶级项目。Storm的出现填补了实时流处理领域的空白,成为大数据生态系统中重要的组成部分,广泛应用于需要实时数据处理的各种场景。
Apache Storm的架构
Apache Storm的架构设计旨在支持分布式和实时的数据流处理。其核心架构由几个关键组件组成,这些组件协同工作以确保高效和可靠的实时计算。
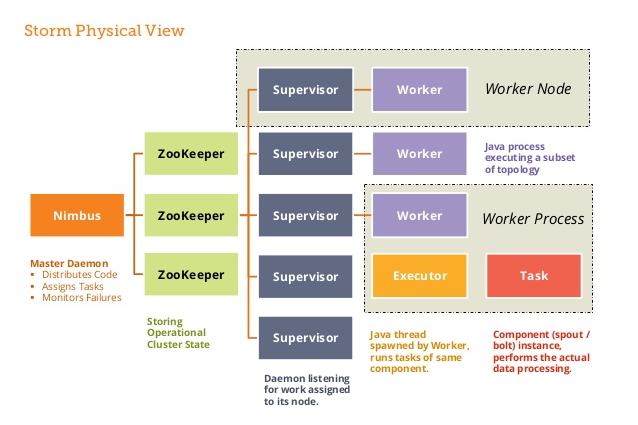
以下是Apache Storm的主要架构组件及其功能:
Nimbus
角色:Storm集群的主节点,类似于Hadoop中的JobTracker。
功能:
- 负责接收和分配拓扑任务。
- 监控拓扑的执行状态。
- 处理故障恢复。
- 提供集群的管理接口。
Nimbus是Storm的大脑,负责整个集群的管理和协调。
Supervisor
角色:Storm集群的工作节点。
功能:
- 运行实际的任务(Spouts和Bolts)。
- 管理本地的资源分配。
- 向Nimbus汇报任务的执行情况。
Supervisor通过运行多个工作进程来执行任务,这些进程称为Worker。
Worker
角色:在Supervisor节点上运行的JVM进程。
功能:
- 执行分配给它的部分拓扑。
每个Worker进程可以运行多个Executor。
Executor
角色:实际执行Spout或Bolt的线程。
功能:
- 一个Executor负责执行一个或多个任务实例。
- 每个任务实例是Spout或Bolt的一个并发实例。
Task
角色:Spout或Bolt的基本执行单元。
功能:
- 每个Task处理数据流中的一部分。
- 由Executor执行。
Zookeeper
角色:分布式协调服务。
功能:
- 用于Nimbus和Supervisor之间的协调。
- 存储集群的元数据和状态信息。
- 处理集群的故障检测和领导者选举。
数据流
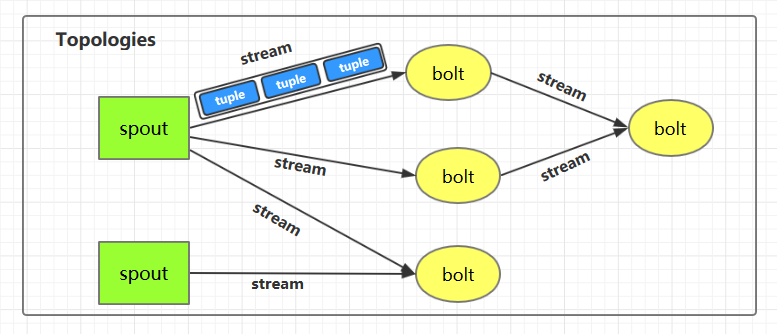
- Spout:数据源组件,负责从外部数据源读取数据并发射到拓扑中。
- Bolt:数据处理组件,负责对流中的数据进行处理和转换,可以执行过滤、聚合、连接等操作。
拓扑
- 拓扑是Storm中的应用程序,由一组Spout和Bolt组成,通过流连接在一起。
- 拓扑一旦提交到Nimbus,就会持续运行,直到被显式终止。
工作流程
- 拓扑提交:用户定义的拓扑被提交到Nimbus。
- 任务分配:Nimbus分配拓扑的执行任务到不同的Supervisor节点。
- 任务执行:Supervisor启动Worker进程执行分配的任务。
- 数据处理:Spout发射数据流,Bolt对数据流进行处理。
- 状态监控:Nimbus监控整个集群的状态,通过Zookeeper协调和管理。
Apache Storm的架构设计使其能够高效地处理大规模的实时数据流,同时提供良好的扩展性和容错性。
其他替代技术方案
在大数据实时流处理领域,随着技术的发展,出现了多种可以替代Apache Storm的技术方案。这些方案各有特点,适用于不同的应用场景。以下是一些常见的替代方案:
Apache Flink:
- 特点:提供真正的流处理能力(与Storm类似),支持事件时间处理、状态管理和复杂事件处理(CEP)。
- 优势:Flink的流处理能力强大,延迟低,支持丰富的窗口操作和状态管理,适合复杂的流式分析应用。
Apache Kafka Streams:
- 特点:Kafka自带的流处理库,简化了在Kafka上构建流处理应用的复杂性。
- 优势:与Kafka无缝集成,易于使用,适合轻量级的流处理任务。
Apache Samza:
- 特点:由LinkedIn开发,专为流处理而设计,通常与Kafka搭配使用。
- 优势:良好的故障恢复能力和灵活的状态管理,适合与Kafka集成的流处理任务。
Apache Beam:
- 特点:提供统一的编程模型,支持批处理和流处理,可以在多种执行引擎(如Apache Flink、Google Cloud Dataflow)上运行。
- 优势:一次编写,随处运行,支持多种执行环境,适合需要跨平台运行的应用。
Spark Streaming/Structured Streaming:
- 特点:Spark 提供的流处理模块,基于微批处理模式(Spark Streaming)和结构化流(Structured Streaming)。
- 优势:与 Spark 生态系统深度集成,适合需要结合批处理和流处理的应用。
这些技术方案各有优劣,选择时需要根据具体的应用需求、现有的技术栈、团队的技术能力以及对云服务的依赖程度等因素来决定。每种方案都有其特定的使用场景,了解它们的特性和限制可以帮助做出更合适的选择。