文章内容如有错误或排版问题,请提交反馈,非常感谢!
Sqoop简介
Sqoop(SQL-to-Hadoop)是一个开源工具,主要用于在Apache Hadoop和传统关系型数据库(如MySQL、PostgreSQL、Oracle、SQL Server等)之间高效传输大规模数据。它简化了数据从关系数据库到Hadoop分布式文件系统(HDFS)、Hive、HBase等的导入,以及从Hadoop导出回关系数据库的过程。
主要特点
- 高效的数据传输:Sqoop利用MapReduce作业来实现并行化的数据导入和导出,能够高效处理大规模数据。
- 支持多种数据源:Sqoop支持大多数常见的关系型数据库以及一些非关系型数据库,通过JDBC驱动程序实现与数据库的连接。
- 自动生成代码:Sqoop可以自动生成用于与数据表交互的Java类,从而简化数据处理过程。
- 灵活的导入导出功能:支持选择性导入特定的表、列、或者使用SQL查询来定制导入的数据。支持将数据导出到关系数据库的特定表中。
- 集成性:Sqoop与Hadoop生态系统中的其他组件(如Hive、HBase、HDFS)紧密集成,能够方便地将数据导入到这些系统中进行处理和分析。
架构与工作原理
Sqoop的架构主要由以下几个部分组成:
- 客户端:Sqoop提供了命令行工具,用户通过命令行接口与Sqoop交互,定义数据传输任务。
- 连接器:Sqoop使用连接器与各种数据库进行交互。连接器是数据库特定的插件,负责处理数据库连接、数据的读取和写入。大多数数据库都可以通过JDBC驱动程序支持Sqoop。
- MapReduce作业:Sqoop利用Hadoop的MapReduce框架执行数据传输任务。数据从数据库中读取后,Sqoop会生成相应的MapReduce作业以并行化的方式将数据导入到Hadoop生态系统中。
- 导入导出任务:
- 导入:从关系数据库导入数据到HDFS、Hive或HBase中。Sqoop通过切分(split)数据表的行来实现并行化的导入。
- 导出:将数据从HDFS导出到关系数据库中,通常用于将处理后的数据回写到数据库中。
使用场景
- 数据仓库集成:将企业数据仓库中的数据导入到Hadoop中进行大规模数据分析和处理。
- 数据迁移:在数据库迁移或升级过程中,将数据从一个数据库系统转移到另一个。
- 数据备份和恢复:定期将数据库中的数据备份到Hadoop中,以提高数据的安全性和可用性。
- 数据分析:从关系数据库中导入数据到Hadoop生态系统中,以利用Hive或Spark进行大数据分析。
- 数据同步:在数据库和Hadoop系统之间保持数据同步,确保数据的一致性和完整性。
Sqoop的设计初衷是为了简化大规模数据的传输和集成,特别是在大数据处理和分析场景中,提供了一种高效且灵活的解决方案。
Sqoop的架构
Sqoop的架构设计旨在简化大规模数据在关系型数据库和Hadoop之间的传输过程。它利用Hadoop的MapReduce框架来实现数据的并行处理,从而提高数据传输的效率和可靠性。
核心组件
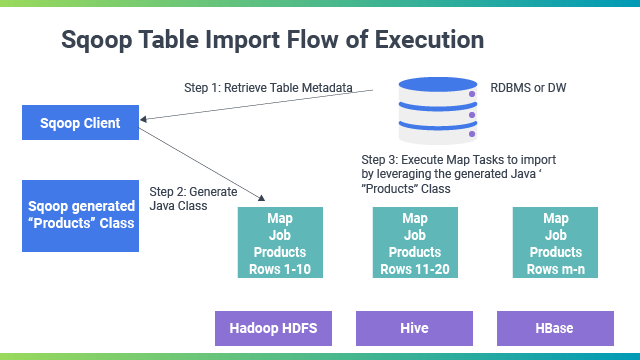
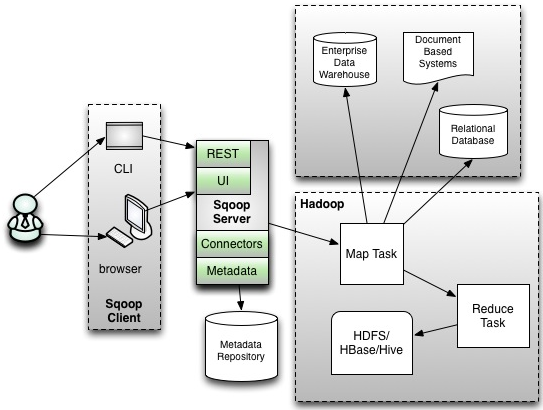
- Sqoop客户端:Sqoop提供了一个命令行工具,用户可以通过它来配置和启动数据导入或导出的任务。用户需要指定源数据库、目标位置、数据表、字段等相关参数。
- 连接器(Connector):Sqoop使用连接器与各种关系型数据库进行交互。连接器是数据库特定的插件,负责处理数据库连接、数据的读取和写入。Sqoop支持多种数据库,如MySQL、Oracle、PostgreSQL、SQL Server等,通过JDBC驱动程序实现与数据库的连接。
- MapReduce作业:Sqoop通过生成和提交MapReduce作业来执行数据传输任务。对于数据导入,Sqoop将从数据库中读取的数据分割成多个部分,每个部分由一个Map任务处理,这样可以实现数据的并行化导入。对于数据导出,Sqoop也会生成相应的MapReduce作业,将HDFS上的数据并行写入到数据库中。
- 代码生成器:Sqoop可以自动生成用于与数据表交互的Java类。这些类封装了数据表的字段和类型信息,用户可以利用这些类在自定义的MapReduce作业中处理数据。
- 元数据存储:Sqoop需要存储和管理一些任务相关的元数据,如任务配置、执行状态等。这些信息通常存储在本地文件系统或HDFS中。
工作流程
- 任务配置:用户通过Sqoop命令行工具定义数据传输任务,指定源数据库、目标位置、数据表、字段、连接器等参数。
- 代码生成(可选):根据用户的配置,Sqoop可以自动生成Java类,用于处理数据表的字段和类型信息。
- 作业生成:Sqoop根据用户的配置生成相应的MapReduce作业,用于数据的导入或导出。作业会根据数据库表的主键或指定的分片列,将数据分成多个片段,以实现并行化处理。
- 任务执行:Sqoop提交生成的MapReduce作业到Hadoop集群。对于导入任务,每个Map任务负责从数据库读取一部分数据并将其写入HDFS、Hive或HBase;对于导出任务,每个Map任务负责将HDFS上的一部分数据写入数据库。
- 任务监控与管理:Sqoop提供日志和状态信息,帮助用户监控任务的执行进度和状态。用户可以查看任务的执行日志,以排查可能出现的问题。
通过这种架构设计,Sqoop能够高效地处理大规模数据的导入和导出任务,利用Hadoop的分布式计算能力实现数据的并行化处理,满足大数据场景下的数据集成需求。
Sqoop的未来
随着大数据技术的发展,许多工具和技术可以替代Sqoop来实现数据在Hadoop和其他系统之间的传输。这些工具通常提供更高的性能、更丰富的功能或更好的用户体验。以下是一些常见的Sqoop替代方案:
- Apache NiFi:NiFi是一个数据流自动化和管理工具,支持从各种数据源(包括关系数据库)采集数据,并将数据传输到Hadoop生态系统中。它提供了丰富的处理器和强大的数据流管理功能。
- Apache Flume:Flume主要用于从各种数据源(尤其是日志数据)收集数据并将其传输到Hadoop中。虽然主要用于流式数据,它也可以配置为处理批量数据。
- Apache Kafka:Kafka是一个分布式流处理平台,通常用于实时数据流传输。通过结合Kafka Connect,可以从关系数据库中捕获变化数据并将其传输到Hadoop或其他系统。
- Apache Gobblin:Gobblin是一个通用的数据集成框架,支持批处理和流式数据的抽取、转换和加载(ETL)。它支持多种数据源和目标,包括Hadoop。
- StreamSets Data Collector:这是一个数据流管理工具,支持从各种数据源实时采集数据并传输到多个目标系统。它提供了一个用户友好的界面和丰富的处理功能。
- Airflow with Custom Scripts:Apache Airflow是一个工作流调度和监控工具,可以通过自定义Python脚本或操作符实现数据的抽取、转换和加载过程。
选择替代 Sqoop 的工具通常取决于具体的使用场景、技术栈、数据量和实时性需求等因素。每种工具都有其独特的优势和适用场景,因此在选择时需要综合考虑业务需求和技术要求。