Presto是什么?
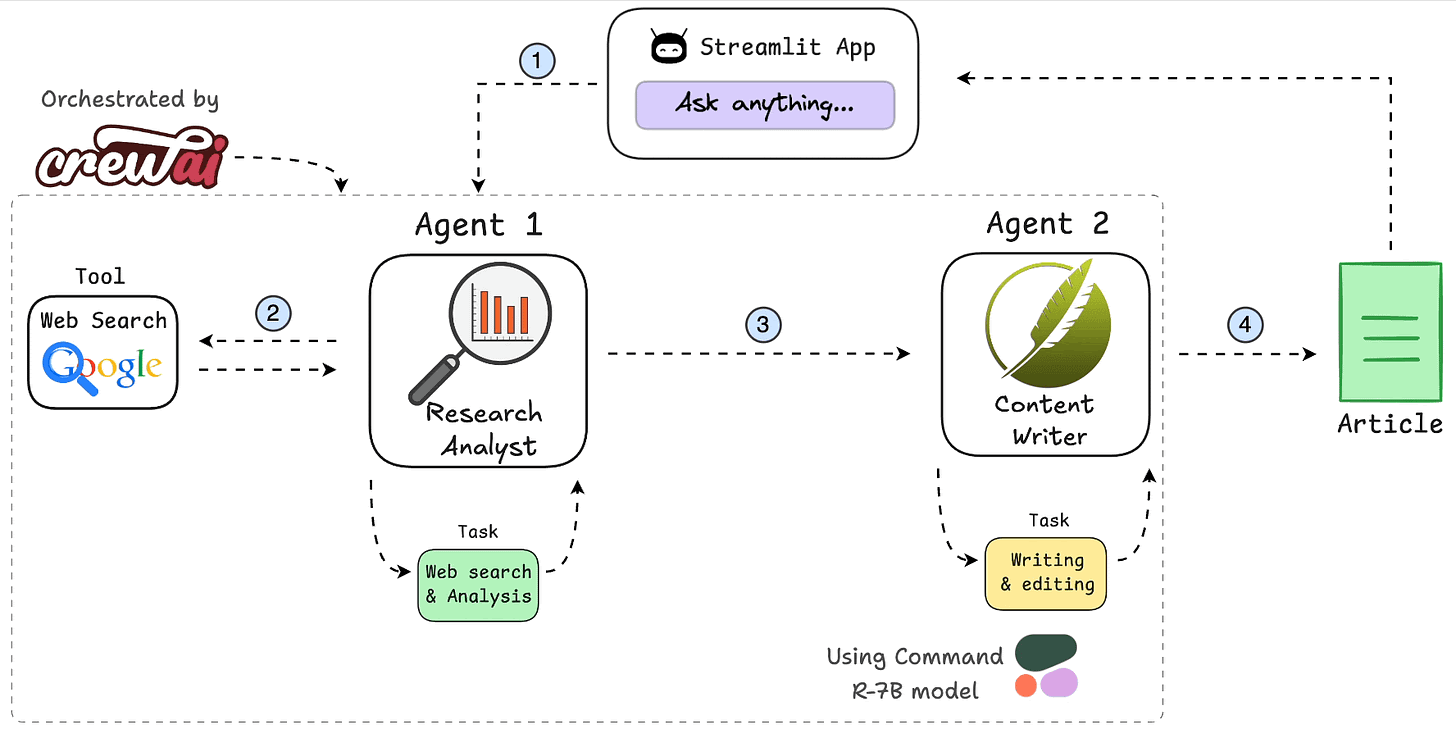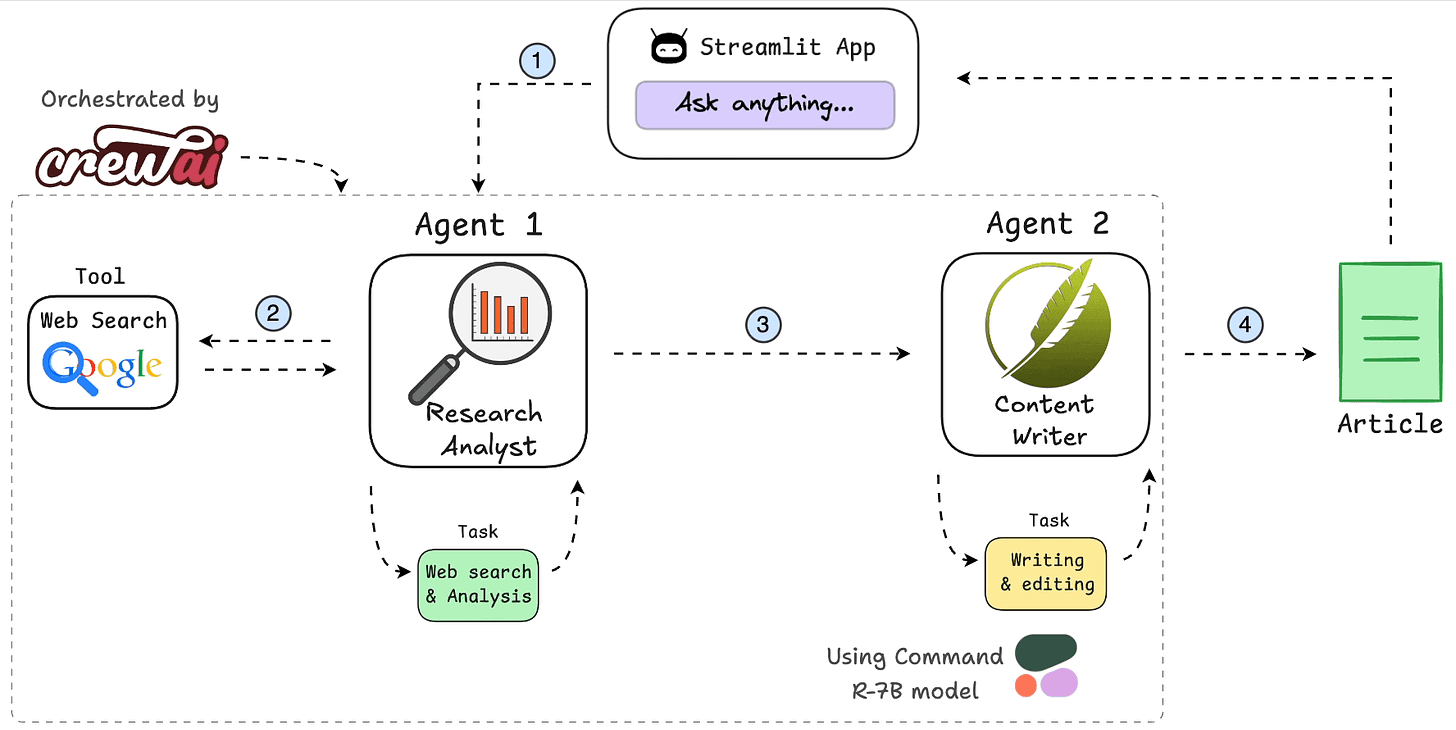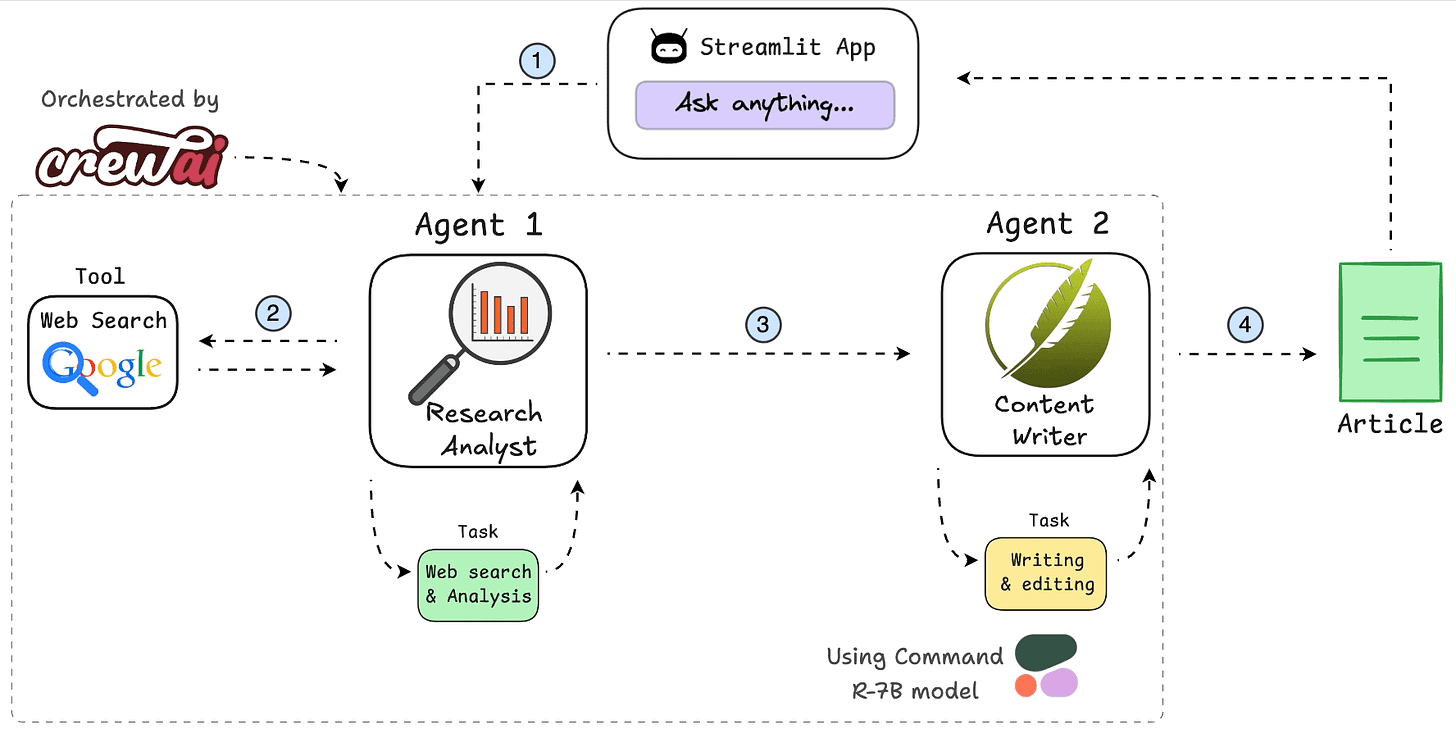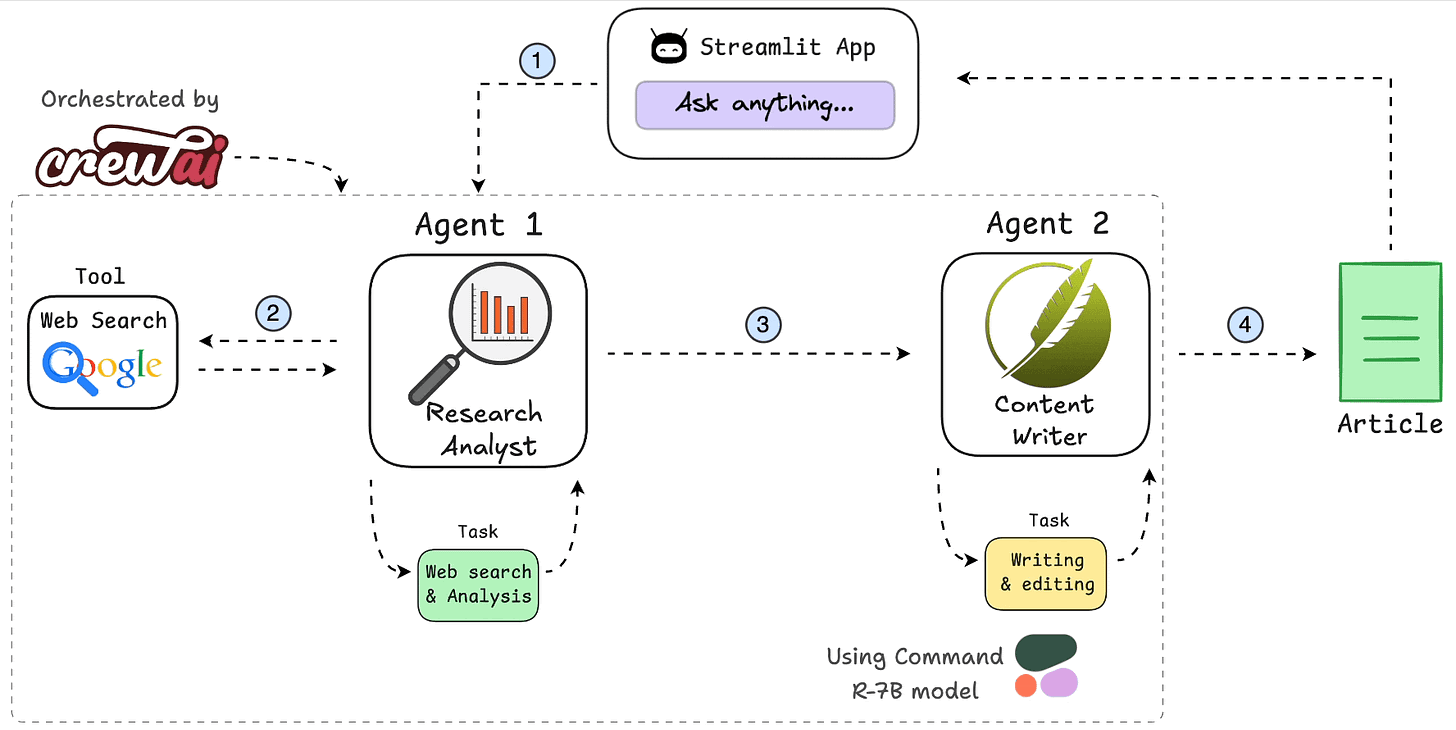
Presto是Facebook开源的MPP(Massive Parallel Processing)SQL引擎,其理念来源于一个叫Volcano的并行数据库,该数据库提出了一个并行执行SQL的模型,它被设计为用来专门进行高速、实时的数据分析。Presto是一个SQL计算引擎,分离计算层和存储层,其不存储数据,通过Connector SPI实现对各种数据源(Storage)的访问。
Hadoop提供了大数据存储与计算的一整套解决方案,但是它采用的是MapReduce计算框架,只适合离线和批量计算,无法满足快速实时的Ad-Hoc(即席分析)查询计算的性能要求。Hive使用MapReduce作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。与Hive比较:
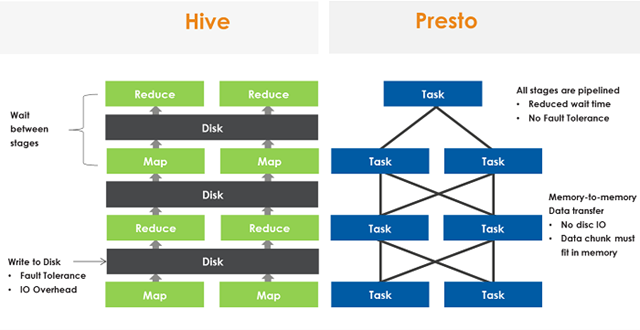
上图显示了MapReduce与Presto的执行过程的不同点,MR每个操作要么需要写磁盘,要么需要等待前一个stage全部完成才开始执行,而Presto将SQL转换为多个stage,每个stage又由多个tasks执行,每个tasks又将分为多个split。所有的task是并行的方式进行允许,stage之间数据是以pipeline形式流式的执行,数据之间的传输也是通过网络以Memory-to-Memory的形式进行,没有磁盘io操作。这也是Presto性能比Hive快很多倍的决定性原因。
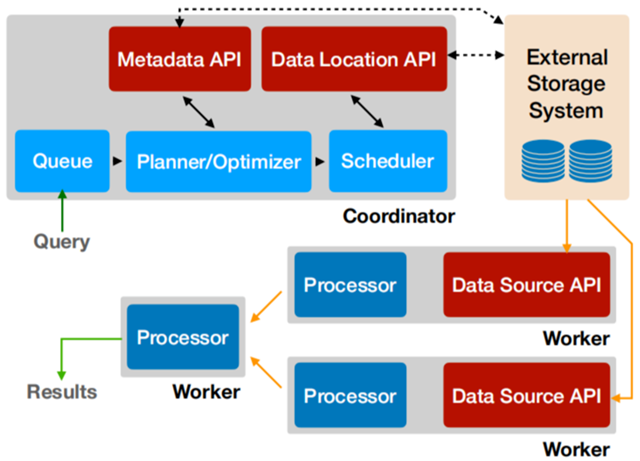
Presto沿用了通用的Master-Slave架构,一个Coordinator,多个Worker。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行;Worker节点负责实际执行查询任务。Presto提供了一套Connector接口,用于读取元信息和原始数据,Presto内置有多种数据源,如Hive、MySQL、Kudu、Kafka等。同时,Presto的扩展机制允许自定义Connector,从而实现对定制数据源的查询。假如配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点通过Hive Connector与HDFS交互,读取原始数据。
Presto的优点:
- Ad-hoc,期望查询时间秒级或几分钟
- 比Hive快10倍
- 支持多数据源,如Hive、Kafka、MySQL、MonogoDB、Redis、JMX等,也可自己实现Connector
- Client Protocol: HTTP+JSON, support various languages (Python, Ruby, PHP, Node.js Java)
- 支持JDBC/ODBC连接
- ANSI SQL,支持窗口函数,join,聚合,复杂查询等
Presto的缺点:
- No fault tolerance;当一个Query分发到多个Worker去执行时,当有一个Worker因为各种原因查询失败,那么Master会感知到,整个Query也就查询失败了,而Presto并没有重试机制,所以需要用户方实现重试机制。
- Memory Limitations for aggregations, huge joins;比如多表join需要很大的内存,由于Presto是纯内存计算,所以当内存不够时,Presto并不会将结果dump到磁盘上,所以查询也就失败了,但最新版本的Presto已支持写磁盘操作。
- MPP (Massively Parallel Processing)架构;这个并不能说其是一个缺点,因为MPP架构就是解决大量数据分析而产生的,但是其缺点也很明显,假如我们访问的是Hive数据源,如果其中一台Worke由于load问题,数据处理很慢,那么整个查询都会受到影响,因为上游需要等待上游结果。
Presto的架构
架构
Presto查询引擎是一个Master-Slave的主从架构,Coordinator是主,worker是从。一个presto集群,由一个Coordinator节点,一个Discovery Server节点(通常内嵌于Coordinator节点中),多个Worker节点组成。其中,Coordinator负责接收查询请求、解析SQL语句、生成执行计划、任务调度给Worker节点执行、worker管理;Worker节点是工作节点,负责实际执行查询任务Task。
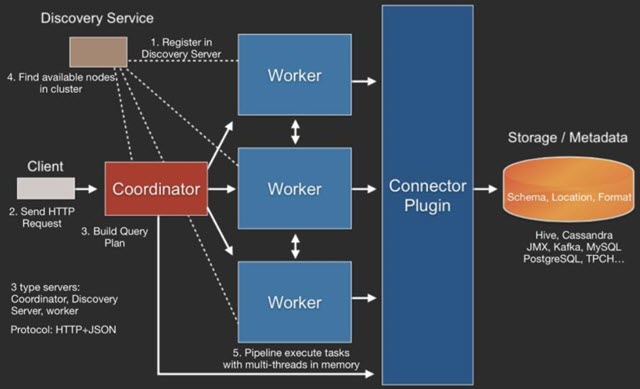
Worker节点启动后向Discovery Server服务注册;Coordinator从Discovery Server获得可以正常工作的Worker节点。
查询执行过程
整体查询流程为:
- Client使用HTTP协议发送一个query请求。
- 通过Discovery Server发现可用的Server。
- Coordinator构建查询计划(Connector插件提供Metadata)
- Coordinator向workers发送任务
- Worker通过Connector插件读取数据
- Worker在内存里执行任务(Worker是纯内存型计算引擎)
- Worker将数据返回给Coordinator,之后再Response Client
SQL执行流程:
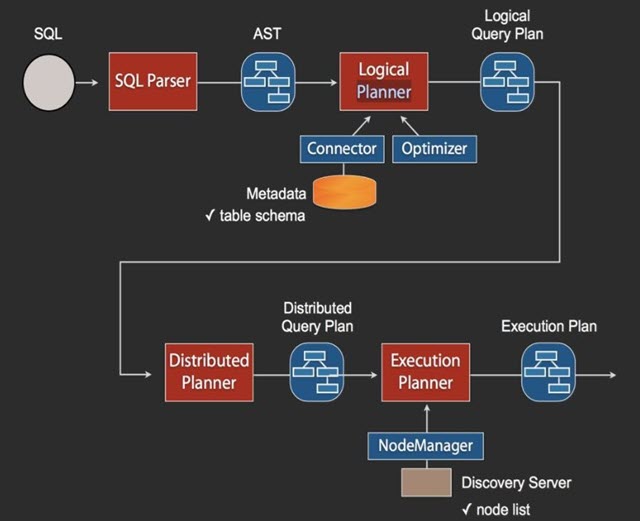
当Coordinator收到一个Query,其SQL执行流程如上图所示。SQL通过Anltr3解析为AST(抽象语法树),然后通过Connector获取原始数据的Metadata信息,这里会有一些优化,比如缓存Metadata信息等,根据Metadata信息生成逻辑计划,然后会依次生成分发计划和执行计划,在执行计划里需要去Discovery里获取可用的node列表,然后根据一定的策略,将这些计划分发到指定的Worker机器上,Worker机器再分别执行。
![]()
Presto包含三类角色,coordinator, discovery, worker。coordinator负责query的解析和调度。discovery负责集群的心跳和角色管理。worker负责执行计算。
- presto-cli提交的查询,实际上是一个http POST请求。查询请求发送到coordinator后,经过词法解析和语法解析,生成抽象语法树,描述查询的执行。
- 执行计划编译器,会根据抽象语法树,层层展开,把语法树所表示的结构,转化成由单个操作所组成的树状的执行结构,称为逻辑执行计划。
- 原始的逻辑执行计划,直接表示用户所期望的操作,未必是性能最优的,在经过一系列性能优化和转写,以及分布式处理后,形成最终的逻辑执行计划。这时的逻辑执行计划,已经包含了map-reduce操作,以及跨机器传输中间计算结果操作。
- scheduler从数据的meta上获取数据的分布,构造split,配合逻辑执行计划,把对应的执行计划调度到对应的worker上。
- 在worker上,逻辑执行计划生成物理执行计划,根据逻辑执行计划,会生成执行的字节码,以及operator列表。operator交由执行驱动来完成计算。
抽象语法树
由语法解析器根据 SQL,解析生成的树状结构,描述 SQL 的执行过程。在下文中,以 SQL select avg(response_size) as a, client_address from localfile.logs.http_request_log group by client_address order by a desc limit 10 为例来描述。
抽象语法树数以 Query 为单位来描述查询,分层次表示不同层的子查询。每一层查询查询包含了几个关键因素:select, from, where, group by, having, order by, limit。其中,from 可以是一个子查询,也可以是一张表。
一个典型的抽象语法树:
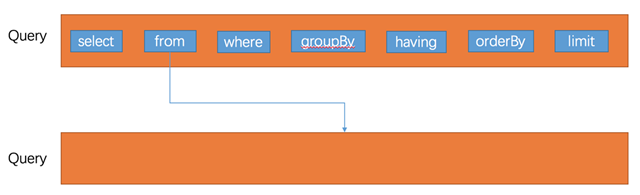
生成逻辑执行计划
抽象语法树树,描述的最原始的用户需求。抽象语法树描述的信息,执行效率上不是最优,执行操作也过于复杂。需要把抽象语法树转化成执行计划。执行计划分成两类,一类是逻辑执行计划,一类是物理执行计划。逻辑执行计划,以树状结构来描述执行,每个节点是最简单的操作。物理执行计划,根据逻辑执行计划生成字节码,交由驱动执行。
转写成逻辑执行计划的过程,包括转写和优化。把抽象语法树转写成由简单操作组成的结点树,然后把树中所有聚合计算节点转写成 map-reduce 形式。并且在 map-reduce 节点中间插入 Exchange 节点。然后,进行一系列优化,把一些能提前加速计算的节点下推,能合并的节点合并。
最后逻辑执行计划按照 Exchange 节点做划分,分成不同的段(fragament),表示不同阶段的的执行计划。在调度时,按照 fragment 调度。
SELECT avg(response_size) as a, client_address FROM localfile.logs.http_request_log GROUP BY client_address ORDER BY a DESC LIMIT 10
以上 SQL 的执行逻辑:
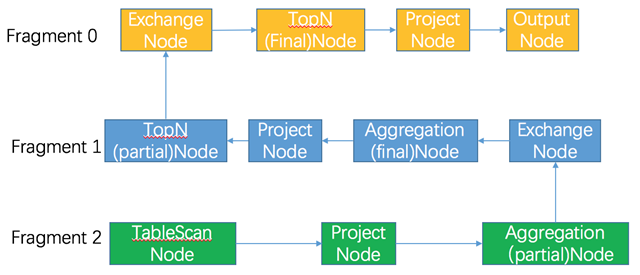
从执行计划中可以看到,agg 节点都是分成 partial 和 final 两步。
调度执行计划到机器上
调度涉及到两个问题,第一,某个 fragment 分配由哪些机器执行;第二,某个 fragment 的计算结果如何输出到下游 fragment。
在调度时,需要为每一个 fragment 指定分配到哪些机器上。从调度上划分,fragment 分三种类型
- 一类是 source 类型由原始数据的存储位置决定 fragment 调度机器,有多少个 source 节点呢?connector 会根据数据的 meta,决定需要读取多少个 split(分片),对于每一个 source 节点,分配一个 split 到一台机器上,如果在配置中指定了 network-topology=flat,则尽量选择 split 所在的机器。
- 一类是 FIXED 类型,主要用于纯计算节点,从集群中选择一台或多台机器分配给某个 fragment。一般只有最终输出节点分配一个机器,中间的计算结果都要分配多台机器。分配的机器数由配置 hash_partition_count 决定。选择机器的方式是随机选择。
- 一类是 SINGLE 类型,只有一台机器,主要用于汇总结果,随机选择一台机器。
对于计算结果输出,根据下游节点的机器个数,也有多种方式,
- 如果下游节点有多台机器,例如 group by 的中间结果,会按照 group by 的 key 计算 hash,按照 hash 值选择一个下游机器输出。对于非 group by 的计算,会随机选择或者 round robin。
- 如果下游节点只有一台机器,会输出到这台机器上。
以下图为例,fragment2 是 source 类型 fragment,有三个 split,所以分配了三台机器。因为这一层计算是 group by 聚合计算,所以输出时按照 group by 的 key 计算 hash,选择下游的某台机器输出。
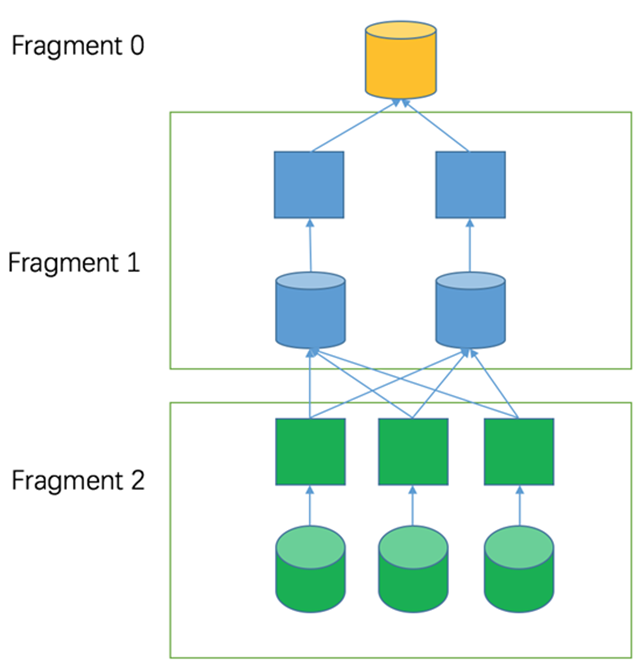
调度之前的任务,都在 coordinator 完成,调度完成后,之后任务发送到 worker 上执行。
生成物理执行计划
逻辑执行计划 fragment 发送到机器上后,由结点树形式转写成 operator list,根据逻辑代码动态编译生成字节码。动态生成字节码,主要是利用编译原理:
- 展开循环
- 根据数据列的类型,直接调用对用的函数,以减少分支跳转语句。
这些手段会更好的利用 CPU 的流水线。
执行驱动
物理执行计划构造生成的 Operator list,交给 Driver 执行。具体计算哪些数据,由加载的 Split 决定。
Operator list 以串联形式处理数据,前一个 operator 的结果作为下一个结果的输入,对于 source 类型的 operator,每一次调用都会获取一份新的数据;对于 Aggregate 的 operator,只有之前所有的 operator 都 finish 之后,才能获取输出结果。
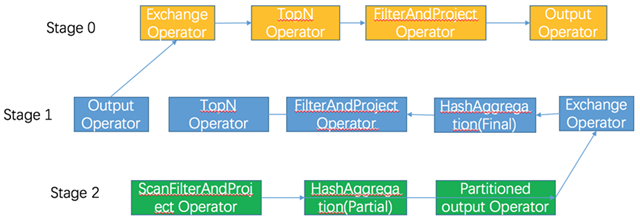
聚合计算
生成的执行计划中,聚合计算都拆分成了两步,分别是 Map、Reduce。
聚合计算的 Operator 有两类,分别是 AggregationOperator 和 HashAggregationOperator。
AggregationOperator 对所有行进行计算,并且把结果更新到一个位置。HashAggregationOperator 使用某一列的 hash 值作为 hash 表的 key,key 相同的行才会把结果保存在一起,用于 group by 类的计算。
聚合计算都是要按照 Map-Reduce 的形式执行。
聚合计算所提供的函数,都要提供四个接口,分别有两个输入,两个输出:
- 接受原始数据的输入
- 接受中间结果的输入
- 输出中间结果
- 输出最终结果。
1+3 构成了 Map 操作 2+4 构成了 Reduce 操作。
以 Avg 为例:
- Map 阶段输入 1,2,3,4
- Map 截断输出 10,4 分别代表 Sum 和 Count
- Reduce 输入 10,4
- Reduce 输出最终平均值 5
我们改造了 Presto 系统,使得 Presto 能够提供缓存功能,就是在 MapReduce 中间加了一层计算,接受中间结果输入和中间结果输出。
函数
函数分为两类,分别是 Scaler 函数和 Aggregate 函数
- Scaler 函数提供数据的转换处理,不保存状态,一个输入产生一个输出。
- Aggregate 函数提供数据的聚合处理,利用已有状态+输入,产生新的状态。
数据模型
Presto 采取三层表结构:
- catalog 对应某一类数据源,例如 hive 的数据,或 mysql 的数据
- schema 对应 mysql 中的数据库
- table 对应 mysql 中的表
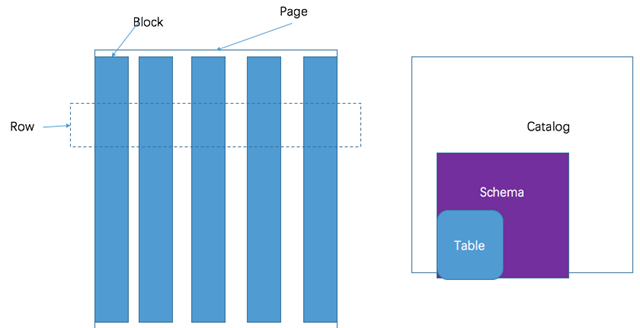 Presto的存储单元包括:
Presto的存储单元包括:
- Page:多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
- Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接 presto。
不同类型的 block:
- array 类型 block,应用于固定宽度的类型,例如 int,long,double。block 由两部分组成
- boolean valueIsNull[] 表示每一行是否有值。
- T values[] 每一行的具体值。
- 可变宽度的 block,应用于 string 类数据,由三部分信息组成
- Slice:所有行的数据拼接起来的字符串。
- int offsets[]: 每一行数据的起始便宜位置。每一行的长度等于下一行的起始便宜减去当前行的起始便宜。
- boolean valueIsNull[] 表示某一行是否有值。如果有某一行无值,那么这一行的便宜量等于上一行的偏移量。
- 固定宽度的 string 类型的 block,所有行的数据拼接成一长串 Slice,每一行的长度固定。
- 字典 block:对于某些列,distinct 值较少,适合使用字典保存。主要有两部分组成:
- 字典,可以是任意一种类型的 block(甚至可以嵌套一个字典 block),block 中的每一行按照顺序排序编号。
- int ids[] 表示每一行数据对应的 value 在字典中的编号。在查找时,首先找到某一行的 id,然后到字典中获取真实的值。
插件
了解了 presto 的数据模型,就可以给 presto 编写插件,来对接自己的存储系统。presto 提供了一套 connector 接口,从自定义存储中读取元数据,以及列存储数据。先看 connector 的基本概念:
- ConnectorMetadata: 管理表的元数据,表的元数据,partition 等信息。在处理请求时,需要获取元信息,以便确认读取的数据的位置。Presto 会传入 filter 条件,以便减少读取的数据的范围。元信息可以从磁盘上读取,也可以缓存在内存中。
- ConnectorSplit: 一个 IOTask 处理的数据的集合,是调度的单元。一个 split 可以对应一个 partition,或多个 partition。
- SplitManager: 根据表的 meta,构造 split。
- SlsPageSource: 根据 split 的信息以及要读取的列信息,从磁盘上读取 0 个或多个 page,供计算引擎计算。
插件能够帮助开发者添加这些功能:
- 对接自己的存储系统。
- 添加自定义数据类型。
- 添加自定义处理函数。
- 自定义权限控制。
- 自定义资源控制。
- 添加 query 事件处理逻辑。
Presto 提供了一个简单的 connector: localfile connector, 可用于参考如何实现自己的 connector。不过 localfile connector 中使用的遍历数据的单元是 cursor, 即一行数据,而不是一个 page。hive 的 connector 中实现了三种类型,parquet connector, orc connector, rcfile connector。

内存管理
Presto 是一款内存计算型的引擎,所以对于内存管理必须做到精细,才能保证 query 有序、顺利的执行,部分发生饿死、死锁等情况。
内存池
Presto 采用逻辑的内存池,来管理不同类型的内存需求。
Presto 把整个内存划分成三个内存池,分别是 SystemPool, ReservedPool, GeneralPool。

- SystemPool 是用来保留给系统使用的,默认为 40% 的内存空间留给系统使用。
- ReservedPool 和 GeneralPool 是用来分配 query 运行时内存的。
- 其中大部分的 query 使用 generalPool。而最大的一个 query,使用 ReservedPool,所以 ReservedPool 的空间等同于一个 query 在一个机器上运行使用的最大空间大小,默认是 10% 的空间。
- General 则享有除了 SystemPool 和 GeneralPool 之外的其他内存空间。
为什么要使用内存池
SystemPool 用于系统使用的内存,例如机器之间传递数据,在内存中会维护 buffer,这部分内存挂载 system 名下。
那么,为什么需要保留区内存呢?并且保留区内存正好等于 query 在机器上使用的最大内存?
如果没有 ReservedPool,那么当 query 非常多,并且把内存空间几乎快要占完的时候,某一个内存消耗比较大的 query 开始运行。但是这时候已经没有内存空间可供这个 query 运行了,这个 query 一直处于挂起状态,等待可用的内存。但是其他的小内存 query 跑完后,又有新的小内存 query 加进来。由于小内存 query 占用内存小,很容易找到可用内存。这种情况下,大内存 query 就一直挂起直到饿死。
所以为了防止出现这种饿死的情况,必须预留出来一块空间,共大内存 query 运行。预留的空间大小等于 query 允许使用的最大内存。Presto 每秒钟,挑出来一个内存占用最大的 query,允许它使用 reservedpool,避免一直没有可用内存供该 query 运行。
内存管理

Presto 内存管理,分两部分:
- query 内存管理。query 划分成很多 task,每个 task 会有一个线程循环获取 task 的状态,包括 task 所用内存。汇总成 query 所用内存。如果 query 的汇总内存超过一定大小,则强制终止该 query。
- 机器内存管理。coordinator 有一个线程,定时的轮训每台机器,查看当前的机器内存状态。
当 query 内存和机器内存汇总之后,coordinator 会挑选出一个内存使用最大的 query,分配给 ReservedPool。
内存管理是由 coordinator 来管理的,coordinator 每秒钟做一次判断,指定某个 query 在所有的机器上都能使用 reserved 内存。那么问题来了,如果某台机器上,,没有运行该 query,那岂不是该机器预留的内存浪费了?为什么不在单台机器上挑出来一个最大的 task 执行。原因还是死锁,假如 query,在其他机器上享有 reserved 内存,很快执行结束。但是在某一台机器上不是最大的 task,一直得不到运行,导致该 query 无法结束。
参考链接: