Apache Oozie简介
Apache Oozie是一个用于管理和协调Hadoop作业的工作流调度系统。它是专为处理复杂的数据处理任务而设计的,允许用户定义和执行由多个Hadoop作业组成的工作流。

核心功能
- 工作流调度:
- Oozie允许用户定义复杂的工作流,这些工作流由一系列的动作(Action)组成,包括MapReduce、Hive、Pig、Shell脚本等。
- 工作流可以指定依赖关系,确保作业按照预定的顺序执行。
- 协调器作业:
- Oozie支持基于时间和数据的协调器作业。用户可以定义作业在特定时间间隔或在特定数据可用时触发。
- 捆绑(Bundle)作业:
- Oozie提供了捆绑功能,允许用户将多个协调器作业打包在一起进行管理和调度。
- 错误处理和重试机制:
- 支持定义错误处理策略,允许对失败的作业进行重试或执行替代动作。
使用场景
- 批处理任务调度: Oozie常用于调度批处理任务,确保复杂的多步骤数据处理管道能够按顺序和依赖关系正确执行。
- 数据驱动的工作流: 通过协调器作业,Oozie可以根据数据的到达触发作业执行,适合数据驱动的ETL任务。
- 时间驱动的工作流: Oozie支持基于时间的调度,例如每天、每周或每月定期运行的任务。
优势和局限
- 优势:
- 与Hadoop生态系统的深度集成,支持多种Hadoop作业类型。
- 提供灵活的工作流定义和调度机制。
- 支持复杂的错误处理和重试策略。
- 局限:
- 工作流定义复杂,学习曲线较陡。
- XML配置可能不够直观,对于大型工作流管理不够便利。
Apache Oozie的架构
Apache Oozie的架构设计旨在高效地管理和协调Hadoop作业。
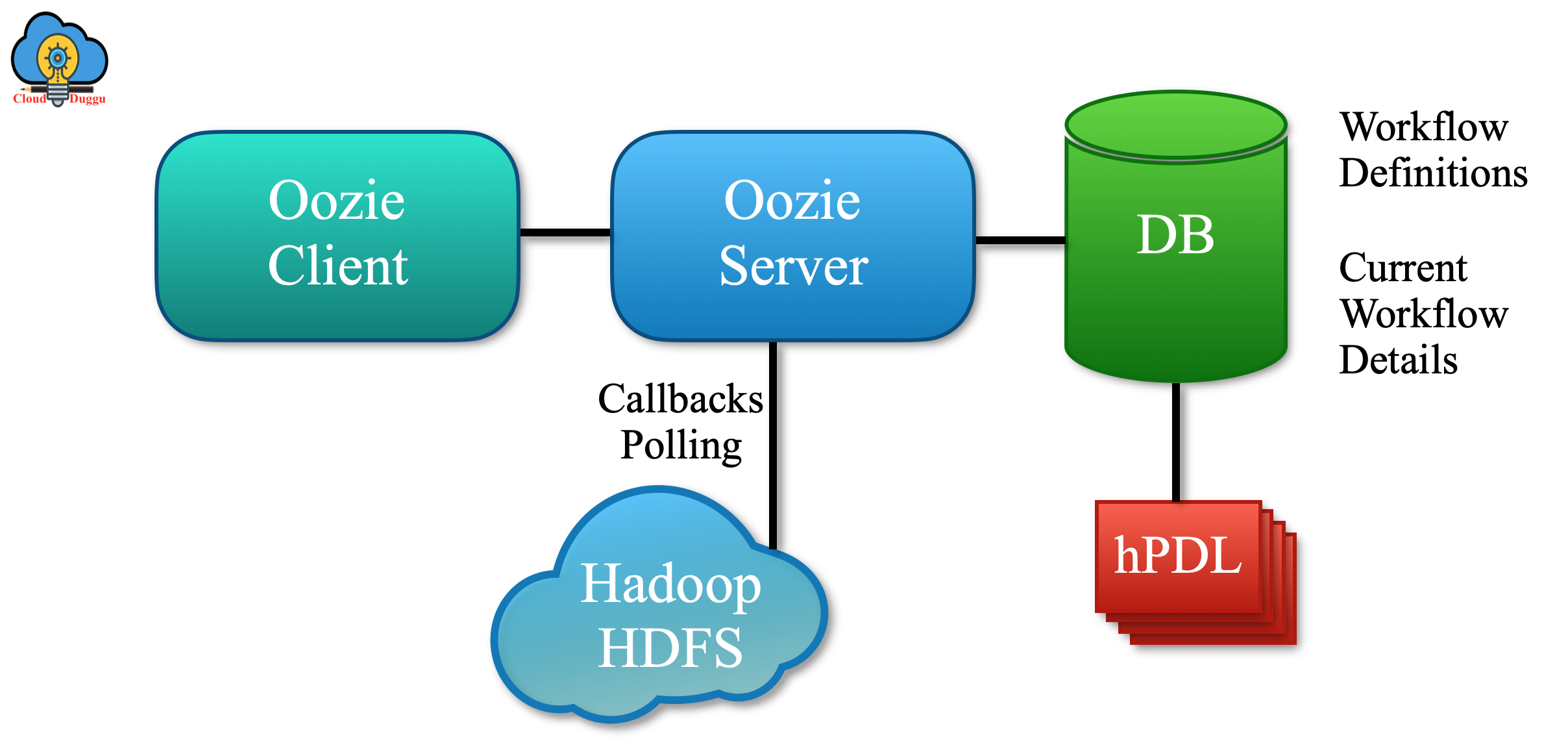
其核心架构由以下几个关键组件组成:
Oozie Server
- 功能:
- Oozie Server是Oozie的核心组件,负责接收、执行和监控工作流和协调器作业。
- 它提供RESTful API,供客户端提交和管理作业。
- 部署:
- 通常部署在Hadoop集群的一个节点上,并与Hadoop的其他服务进行集成。
Oozie Client
- 功能:
- Oozie Client提供命令行工具和Java API,供用户提交、管理和查询作业。
- 通过客户端,用户可以与Oozie Server交互,提交工作流定义和配置文件。
Database
功能:
- Oozie使用关系型数据库(如MySQL、PostgreSQL、Derby)来存储作业的元数据和状态信息。
- 数据库用于持久化工作流定义、作业实例、执行状态和历史记录。
Workflow Engine
- 功能:
- 工作流引擎负责解析和执行用户提交的工作流定义。
- 它管理工作流的生命周期,包括启动、暂停、恢复和终止。
- 工作流定义:
- 工作流使用XML格式定义,包含动作节点和控制流节点。
- 动作节点定义具体的任务,如MapReduce、Hive、Pig、Shell脚本等。
- 控制流节点用于定义工作流的执行逻辑,如分支、合并和决策。
Action Nodes
- 功能:
- Action Nodes是工作流中的实际执行单元,负责执行具体的Hadoop作业或任务。
- Oozie支持多种类型的动作节点,包括MapReduce、Hive、Pig、Java、Shell等。
Control Nodes
- 功能:
- Control Nodes用于控制工作流的执行流,包括定义开始、结束、决策、分支和合并等逻辑。
- 常见的控制节点有start、end、kill、decision、fork、join等。
Web Console
- 功能:
- Oozie提供基于Web的用户界面,用户可以通过浏览器查看和管理Oozie作业。
- Web Console提供作业的状态查看、日志监控和错误诊断功能。
Apache Oozie的架构设计注重与Hadoop生态系统的集成,通过其核心组件和灵活的工作流定义方式,提供了强大的作业调度和管理能力。Oozie的模块化设计使其能够高效地处理复杂的数据处理任务,并支持多种类型的Hadoop作业。通过RESTful API和Web Console,用户可以方便地与Oozie进行交互,管理和监控其数据处理工作流。
Apache Oozie的替代方案
Apache Oozie是一个流行的工作流调度系统,专门用于管理和协调Hadoop生态系统中的作业。然而,随着大数据技术的发展,出现了许多其他工具和框架,可以作为Oozie的替代方案。这些替代方案各有其独特的特性和优势,适用于不同的使用场景。以下是一些常见的Apache Oozie替代方案:
Apache Airflow
Apache Airflow是一个开源的工作流自动化和调度平台,最初由Airbnb开发。
特点:
- 使用Python代码定义工作流,直观且灵活。
- 提供丰富的可视化界面,用于监控和管理工作流。
- 支持动态生成工作流,适合复杂的数据工程任务。
- 强大的社区支持和丰富的插件生态系统。
适用场景:
- 适合需要灵活定义和动态生成工作流的场景。
- 数据工程和数据科学工作流的自动化和调度。
Apache NiFi
Apache NiFi是一个数据流管理和自动化工具,专注于数据流的自动化和管理。
特点:
- 提供基于Web的用户界面,支持拖放操作。
- 支持实时数据流处理和复杂的数据路由。
- 丰富的处理器库,支持多种数据源和目标。
适用场景:
- 实时数据流处理和复杂的数据集成任务。
- 数据管道的可视化设计和管理。
Apache Spark with Apache Livy
- Apache Spark 是一个统一的分析引擎,支持大规模数据处理。Apache Livy 是一个用于与 Spark 交互的 REST 服务。
特点:
- Spark 提供强大的并行处理能力和丰富的 API。
- Livy 提供 REST 接口,便于与其他系统集成。
- 支持批处理、流处理和机器学习任务。
适用场景:
- 需要高性能数据处理和分析的场景。
- 复杂的数据管道和机器学习工作流。
Luigi
概述:
- Luigi 是一个由 Spotify 开发的 Python 工具,用于构建复杂的管道。
特点:
- 使用 Python 代码定义任务和依赖关系。
- 支持本地和远程任务执行。
- 提供简单的命令行工具和可视化界面。
适用场景:
- 适合中小规模的数据管道和任务调度。
- 数据工程和批处理任务的自动化。
Azkaban
Azkaban 是一个批量工作流调度和管理工具,由 LinkedIn 开发。
特点:
- 提供基于 Web 的用户界面,支持工作流的可视化管理。
- 支持工作流的版本控制和历史记录。
- 简单的配置文件格式,易于定义和管理工作流。
适用场景:
- 需要简单、易用的批量工作流调度的场景。
- 数据工程和 ETL 任务的管理。
总结
选择合适的工作流调度工具取决于具体的业务需求、团队的技术栈以及现有的基础设施。Apache Oozie 是 Hadoop 生态系统中的经典工具,但随着技术的发展,其他工具如 Apache Airflow 和 Apache NiFi 等在灵活性、可视化和集成能力方面提供了更多的选择。了解每种工具的特点和适用场景可以帮助团队更好地选择适合的解决方案。