Kylin简介
Apache Kylin 是一个开源的分布式分析型数据仓库,专门用于大规模数据集的实时分析。它最初由 eBay 开发,并于 2015 年成为 Apache 软件基金会的顶级项目。Kylin 通过提供 SQL 接口和多维分析(OLAP)功能,使用户能够在大数据平台上进行快速查询和分析。
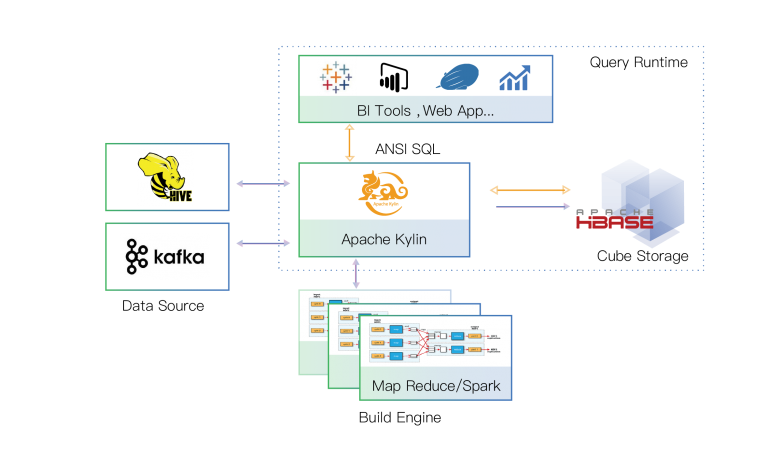
核心功能和特性
- OLAP on Hadoop:Kylin 旨在解决大数据环境中的多维分析问题。它能够在 Hadoop 上进行高性能的 OLAP 查询,支持大规模数据集。
- 快速查询:通过预计算技术,Kylin 能够将复杂的 SQL 查询转换为高效的多维分析,支持亚秒级的查询响应时间。
- 多维数据模型:支持星型和雪花型数据模型,允许用户定义维度和度量,实现复杂的多维分析。
- SQL 接口:提供标准的 ANSI SQL 接口,用户可以使用熟悉的 SQL 语法进行数据查询和分析。
- 支持多种数据源:可以从多种数据源导入数据,包括 Hive、Kafka 等,适用于不同的业务场景。
- 可扩展性:由于其分布式架构,Kylin 可以处理 PB 级别的数据量,适合企业级应用。
- 与 BI 工具集成:支持与各种商业智能(BI)工具的集成,如 Tableau、Power BI 等,方便可视化分析。
使用场景
- 大数据分析:适用于需要处理和分析大规模数据集的场景,如用户行为分析、营销数据分析等。
- 实时分析:通过与 Kafka 集成,Kylin 可以实现准实时的数据分析,适合需要实时决策的业务场景。
- 商业智能:与 BI 工具的无缝集成,使企业能够轻松地在大数据平台上进行数据可视化和商业智能分析。
优势与挑战
优势:
- 高性能:通过预计算和 Cube 技术,Kylin 能够提供亚秒级的查询响应。
- 扩展性:可以处理海量数据,适合大数据分析场景。
- 灵活性:支持多种数据源和复杂的多维数据模型。
挑战:
- Cube 构建和存储可能会消耗大量资源,特别是在数据维度和粒度较高的情况下。
- 需要一定的学习成本来理解和优化数据模型和 Cube 构建策略。
Kylin的架构
作为一套旨在对Hadoop环境下分析流程进行加速,而且能够与SQL兼容性工具顺利协作的解决方案,Kylin成功将SQL接口与多维分析机制(OLAP)引入Hadoop,旨在对规模极为庞大的数据集加以支持。Kylin的高层架构,如下所示:
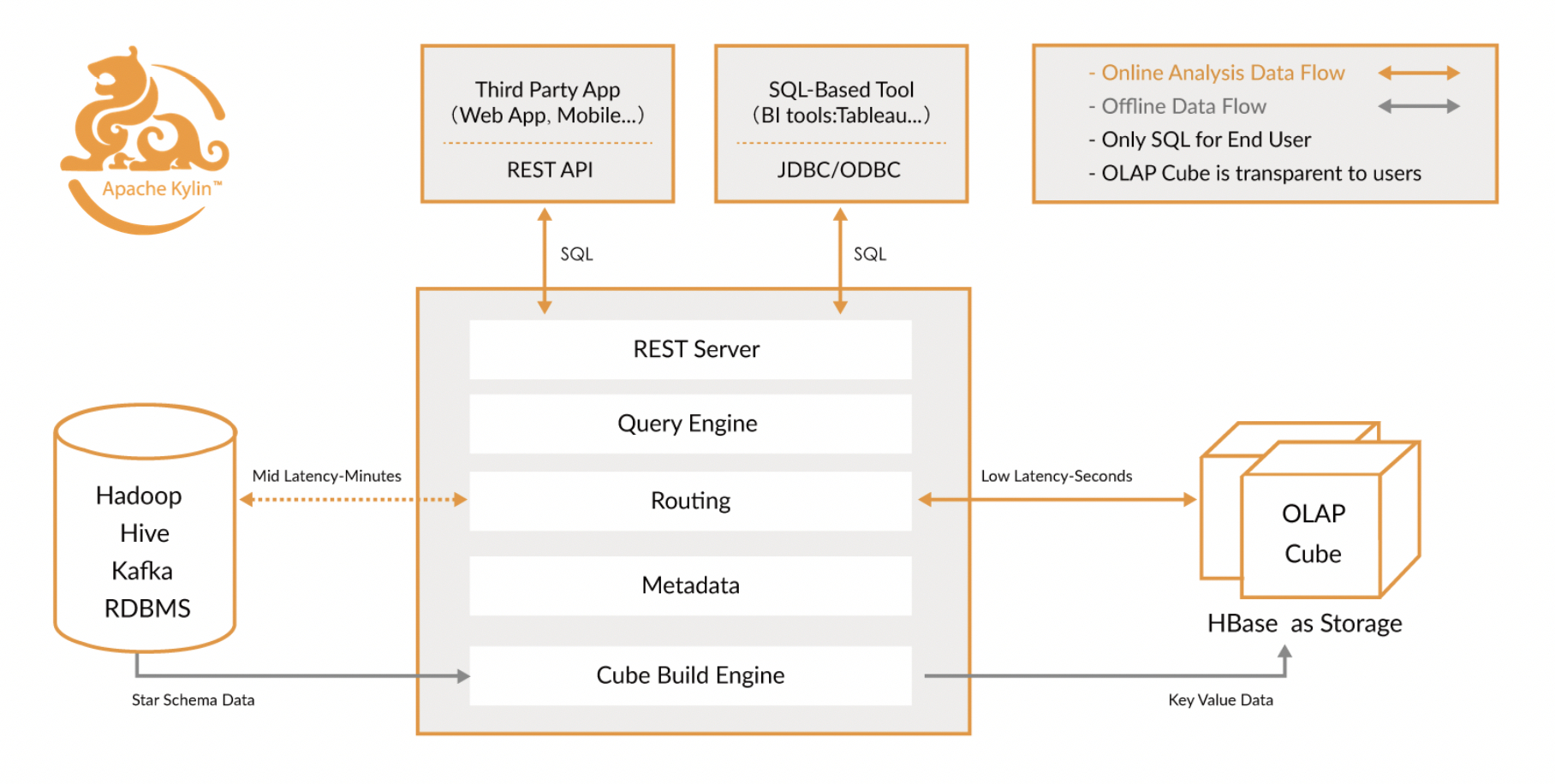
Apache Kylin 的架构设计旨在高效地支持大规模数据集的多维分析(OLAP)。它通过预计算技术实现了快速的查询响应时间。以下是 Kylin 的详细架构介绍:
数据源层
- 数据源:
- Kylin 通常从 Hadoop 生态系统中的数据源(如 Apache Hive、Apache Kafka)中获取数据。这些数据源提供了原始数据,Kylin 通过 ETL(Extract, Transform, Load)过程将数据加载到其分析系统中。
数据准备层
- ETL 过程:
- 在加载数据之前,Kylin 需要对数据进行清洗和转换。这个过程通常使用 Hadoop 的 MapReduce 或 Spark 任务来完成。
- 数据准备包括将原始数据转换为适合多维分析的格式,并加载到 Hive 表中。
Cube 构建层
- Cube 构建:
- Kylin 的核心是数据立方体(Cube)的构建。Cube 是预计算的多维数据结构,包含了所有可能的维度组合及其聚合结果。
- Cube 构建过程包括数据的抽取、转换和加载,以及对不同维度组合的聚合计算。
- 这个过程使用 MapReduce 或 Spark 作业在分布式环境中执行,以处理大规模数据。
存储层
- HBase 存储:
- 构建好的 Cube 数据通常存储在 Apache HBase 中。HBase 是一个分布式、可扩展的 NoSQL 数据库,适合存储大规模结构化数据。
- HBase 提供了快速的数据读取能力,支持 Kylin 在查询时的高效访问。
查询层
- 查询引擎:
- Kylin 提供了一个高性能的查询引擎,支持标准的 SQL 查询。用户可以通过 JDBC、ODBC 或 RESTful API 与 Kylin 交互。
- 查询引擎负责解析 SQL 查询,识别需要的数据立方体,并从 HBase 中检索预计算的结果。
- 查询优化:
- Kylin 的查询引擎具有智能优化功能,能够选择最优的路径来获取数据,以提高查询性能。
管理和监控层
- Web UI:
- Kylin 提供了一个用户友好的 Web 界面,用于管理和监控 Cube 的构建和查询。
- 用户可以通过 Web UI 定义数据模型、启动 Cube 构建作业、监控系统性能和查询日志等。
- API 接口:
- 除了 Web UI,Kylin 还提供了 RESTful API,方便用户进行自动化管理和集成。
扩展和集成
- 与 BI 工具集成:
- Kylin 支持与各种商业智能(BI)工具的集成,如 Tableau、Power BI 等,方便用户进行数据可视化和分析。
- 可扩展性:
- Kylin 的分布式架构使其能够处理 PB 级别的数据,适合企业级应用。
Kylin的处境
在大数据分析领域,除了 Apache Kylin,还有许多其他开源的 OLAP(在线分析处理)分析引擎可供选择。每个工具都有其独特的功能和适用场景。以下是一些常见的开源 OLAP 分析引擎:
- Apache Druid:
- 特点: Druid 是一个高性能的实时分析数据库,专注于低延迟的数据摄取和查询。它适合处理实时流数据和批量历史数据。
- 优势: 支持实时数据摄取、快速的 OLAP 查询、时间序列分析和丰富的聚合功能。
- ClickHouse:
- 特点: 由 Yandex 开发的一个列式数据库管理系统,以其快速的查询性能和高压缩率著称。
- 优势: 能够处理实时数据分析,支持复杂查询和数据聚合,适合在线广告、流量分析等场景。
- Apache Pinot:
- 特点: 专为低延迟的 OLAP 查询而设计,支持从 Apache Kafka 等流数据源进行实时数据摄取。
- 优势: 适用于需要实时仪表盘和分析的场景,如用户行为分析、商业智能等。
- Presto (Trino):
- 特点: 一个分布式 SQL 查询引擎,支持从多个数据源进行交互式分析。Presto 适用于需要查询多种数据存储系统的场景。
- 优势: 提供高效的查询性能和灵活性,支持各种数据源,包括 HDFS、S3、MySQL 等。
- Apache Hive:
- 特点: 虽然 Hive 最初是为批处理设计的,但通过改进和优化,它也支持一些 OLAP 查询功能。
- 优势: 依托 Hadoop 生态系统,支持大规模数据的批处理和分析。
- Apache Impala:
- 特点: Cloudera 开发的一个分布式 SQL 查询引擎,专注于提供快速、低延迟的查询性能。
- 优势: 直接查询存储在 HDFS 和 HBase 中的数据,适合需要低延迟的交互式查询场景。
- Greenplum:
- 特点: 基于 PostgreSQL 的大规模并行处理数据库系统,适用于数据仓库和大数据分析。
- 优势: 提供强大的 SQL 支持和扩展能力,适合复杂的分析任务。
- Apache Cassandra with Apache Spark:
- 特点: 虽然 Cassandra 本身是一个分布式 NoSQL 数据库,但结合 Apache Spark,可以实现高效的 OLAP 分析。
- 优势: 适合需要高可用性和可扩展性的应用,尤其是在需要实时分析的场景中。
每个工具都有其独特的优点和适用场景,选择合适的 OLAP 引擎通常取决于具体的业务需求、数据规模、实时性要求以及现有的技术栈。
参考链接:


