这篇一开始文章整理于2014年,在此的7~8年时间里,Hadoop已经发生了很多变化,但最为核心的内容并没有变化那么多,当时的文章还是有一定的参考意义。再次重新做下整理。
Hadoop的概要介绍
Hadoop,是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。该平台使用的是面向对象编程语言Java实现的,具有良好的可移植性。
Hadoop的发展历史
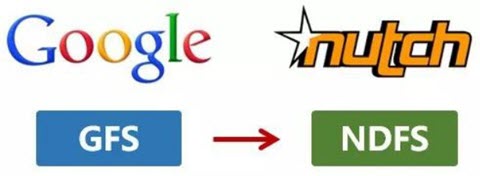
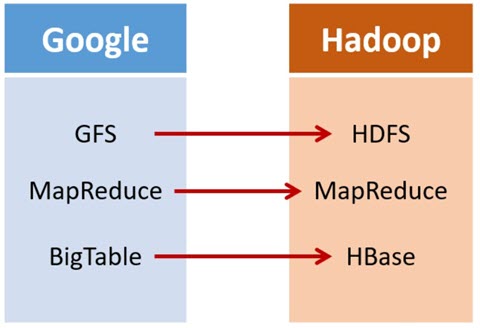
1998年9月4日,Google公司在美国硅谷成立,作为互联网搜索引擎,需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。2003年,Google发表了一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS(Google File System)。这是Google公司为了存储海量搜索数据而设计的专用文件系统。第二年,也就是2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)
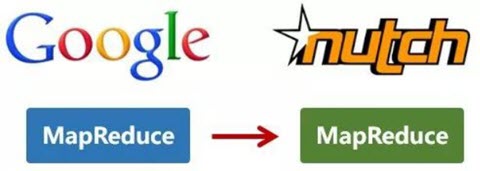
还是2004年,Google又发表了一篇技术学术论文,介绍自己的MapReduce编程模型。这个编程模型,用于大规模数据集(大于1TB)的并行分析运算。第二年(2005年),Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。
2006年,当时依然很厉害的Yahoo(雅虎)公司,招安了Doug Cutting。
这里要补充说明一下雅虎招安Doug的背景:2004年之前,作为互联网开拓者的雅虎,是使用Google搜索引擎作为自家搜索服务的。在2004年开始,雅虎放弃了Google,开始自己研发搜索引擎。所以。。。
加盟Yahoo之后,Doug Cutting将NDFS和MapReduce进行了升级改造,并重新命名为Hadoop(NDFS也改名为HDFS,Hadoop Distributed File System)。
这个,就是后来大名鼎鼎的大数据框架系统——Hadoop的由来。而Doug Cutting,则被人们称为Hadoop之父。Hadoop这个名字,实际上是Doug Cutting他儿子的黄色玩具大象的名字。所以,Hadoop的Logo,就是一只奔跑的黄色大象。

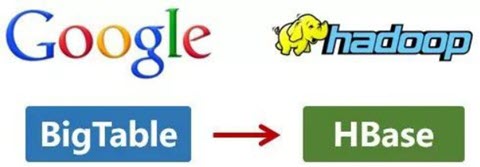
还是2006年,Google又发论文了。这次,它们介绍了自己的BigTable。这是一种分布式数据存储系统,一种用来处理海量数据的非关系型数据库。
Doug Cutting当然没有放过,在自己的hadoop系统里面,引入了BigTable,并命名为HBase。
所以,Hadoop的核心部分,基本上都有Google的影子。
2008年1月,Hadoop成功上位,正式成为Apache基金会的顶级项目。同年2月,Yahoo宣布建成了一个拥有1万个内核的Hadoop集群,并将自己的搜索引擎产品部署在上面。7月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,用时209秒。此后,Hadoop便进入了高速发展期,直至现在。
Hadoop1.0
Hadoop是一个开发和运行处理大规模数据的软件平台,是Apache的一个用JAVA语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。Hadoop框架中最核心设计就是:MapReduce和HDFS。MapReduce提供了对数据的计算,HDFS提供了海量数据的存储。
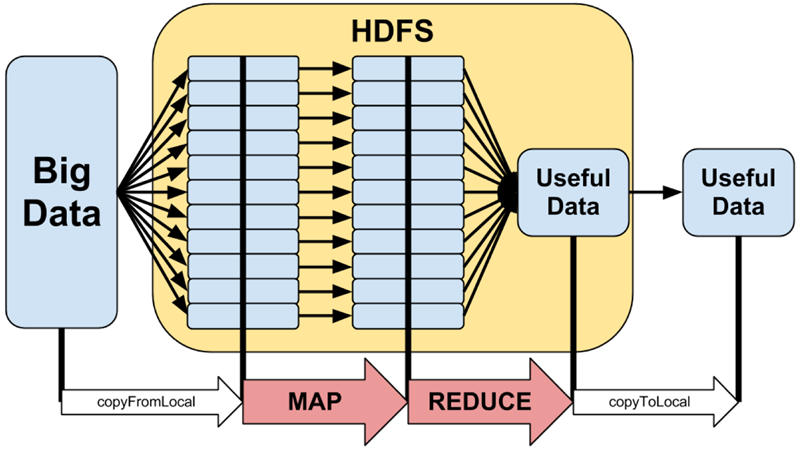
MapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释MapReduce就是”任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
MapReduce
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,”Map(展开)”就是将一个任务分解成为多个任务,”Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执行;另一种是任务之间有相互的依赖,先后顺序不能够颠倒,这类任务是无法并行处理的。
在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。任务分解处理以后,那就需要将处理以后的结果再汇总起来,这就是Reduce要做的工作。
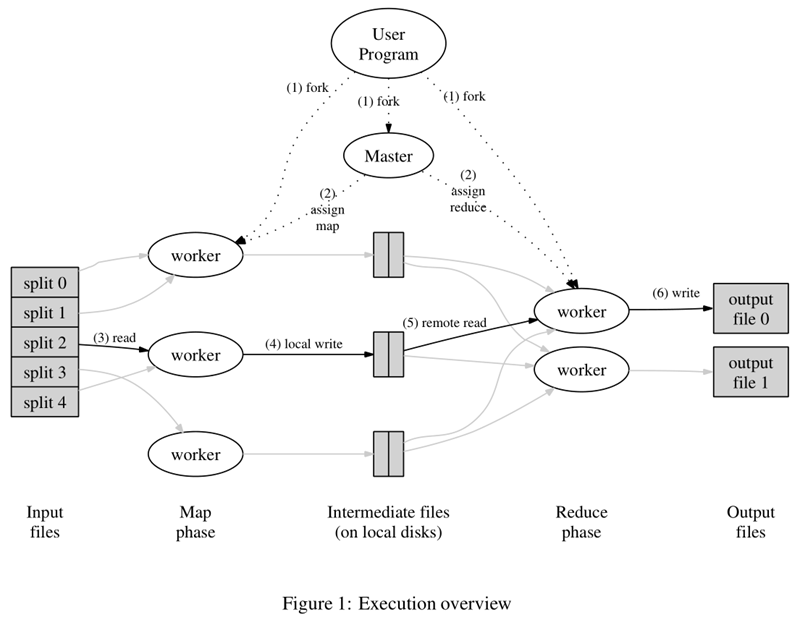
上图是论文里给出的流程图。一切都是从最上方的User Program开始的,User Program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
- MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
- user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或者Reduce作业),worker的数量也是可以由用户指定的。
- 被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
- 缓存的中间键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
- master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
- reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
- 当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(HDFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(HDFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。
上诉流程分为三个阶段。第一阶段是准备阶段,包括1、2,主角是MapReduce库,完成拆分作业和拷贝用户程序等任务;第二阶段是运行阶段,包括3、4、5、6,主角是用户定义的map和reduce函数,每个小作业都独立运行着;第三阶段是扫尾阶段,这时作业已经完成,作业结果被放在输出文件里,就看用户想怎么处理这些输出了。
在Map前还可能会对输入的数据有Split(分割)的过程,保证任务并行效率,在Map之后还会有Shuffle(混合)的过程,对于提高Reduce的效率以及减小数据传输的压力有很大的帮助。Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。要想理解MapReduce,Shuffle是必须要了解的。
MapReduce的Shuffle过程
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。
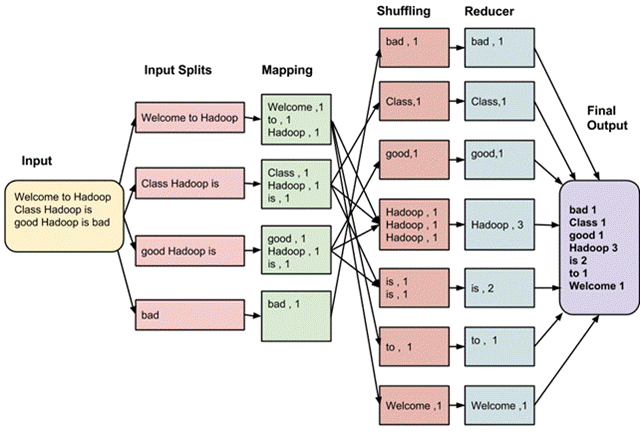
可能大家更熟悉的是Java API里的Collections.shuffle(List)方法,它会随机地打乱参数list里的元素顺序。如果你不知道MapReduce里Shuffle是什么,那么请看这张图:
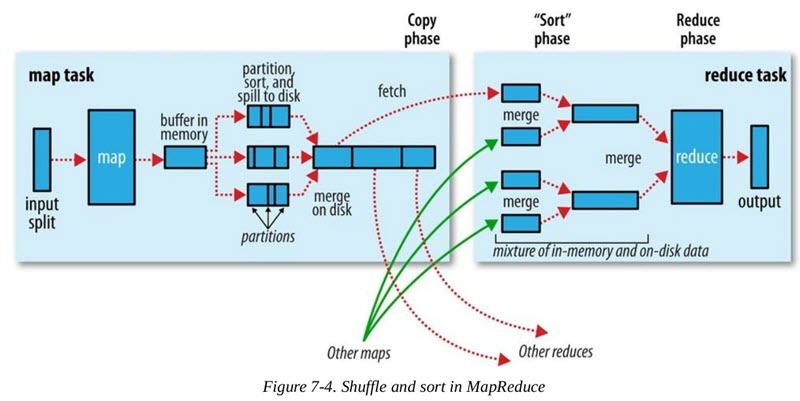
实际上,从Map Task任务中的map()方法中的最后一步调用即输出中间数据开始,一直到Reduce Task任务开始执行reduce()方法结束,这一中间处理过程就被称为MapReduce的Shuffle。Shuffle过程分为两个阶段:Map端的shuffle阶段和Reduce端的Shuffle阶段。
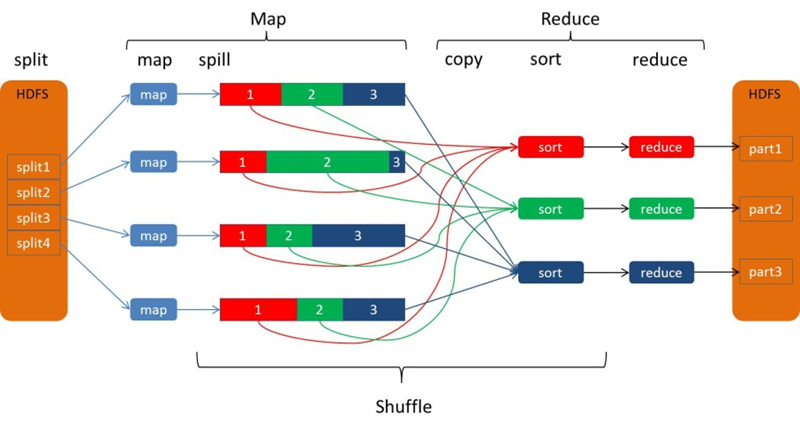
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示:
Spill过程包括输出、排序、溢写、合并等步骤,如图所示:
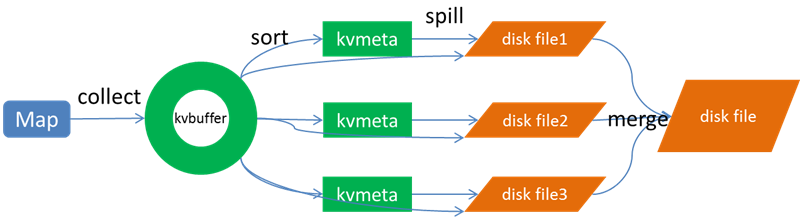
1、Collect阶段
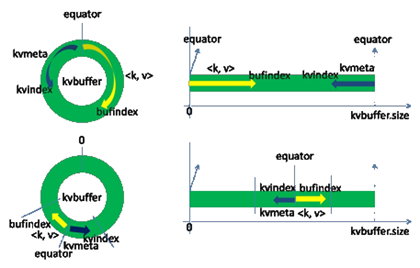
每个Map任务不断地以<key,value>对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。这个数据结构其实就是个字节数组,叫Kvbuffer,名如其义,但是这里面不光放置了<key,value>数据,还放置了一些索引数据,给放置索引数据的区域起了一个Kvmeta的别名,在Kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。<key,value>数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次Spill之后都会更新一次。初始的分界点是0,<key,value>数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:
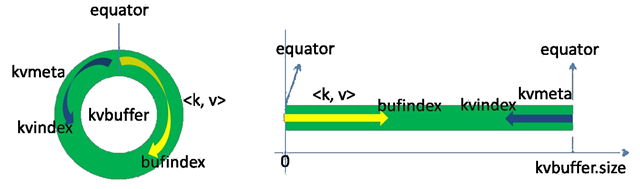 Kvbuffer 的存放指针 bufindex 是一直闷着头地向上增长,比如 bufindex 初始值为 0,一个 Int 型的 key 写完之后,bufindex 增长为 4,一个 Int 型的 value 写完之后,bufindex 增长为 8。
Kvbuffer 的存放指针 bufindex 是一直闷着头地向上增长,比如 bufindex 初始值为 0,一个 Int 型的 key 写完之后,bufindex 增长为 4,一个 Int 型的 value 写完之后,bufindex 增长为 8。
索引是对 <key,value> 在 kvbuffer 中的索引,是个四元组,包括:value 的起始位置、key 的起始位置、partition 值、value 的长度,占用四个 Int 长度,Kvmeta 的存放指针 Kvindex 每次都是向下跳四个“格子”,然后再向上一个格子一个格子地填充四元组的数据。比如 Kvindex 初始位置是 -4,当第一个 <key,value> 写完之后,(Kvindex+0) 的位置存放 value 的起始位置、(Kvindex+1) 的位置存放 key 的起始位置、(Kvindex+2) 的位置存放 partition 的值、(Kvindex+3) 的位置存放 value 的长度,然后 Kvindex 跳到 -8 位置,等第二个 <key,value> 和索引写完之后,Kvindex 跳到 -32 位置。
Kvbuffer 的大小虽然可以通过参数设置,但是总共就那么大,<key,value> 和索引不断地增加,加着加着,Kvbuffer 总有不够用的那天,那怎么办?把数据从内存刷到磁盘上再接着往内存写数据,把 Kvbuffer 中的数据刷到磁盘上的过程就叫 Spill,多么明了的叫法,内存中的数据满了就自动地 spill 到具有更大空间的磁盘。
关于 Spill 触发的条件,也就是 Kvbuffer 用到什么程度开始 Spill,还是要讲究一下的。如果把 Kvbuffer 用得死死得,一点缝都不剩的时候再开始 Spill,那 Map 任务就需要等 Spill 完成腾出空间之后才能继续写数据;如果 Kvbuffer 只是满到一定程度,比如 80% 的时候就开始 Spill,那在 Spill 的同时,Map 任务还能继续写数据,如果 Spill 够快,Map 可能都不需要为空闲空间而发愁。两利相衡取其大,一般选择后者。
Spill 这个重要的过程是由 Spill 线程承担,Spill 线程从 Map 任务接到“命令”之后就开始正式干活,干的活叫 SortAndSpill,原来不仅仅是 Spill,在 Spill 之前还有个颇具争议性的 Sort。
在 MapTask 任务的业务处理方法 map() 中,最后一步通过 OutputCollector.collect(key,value) 或 context.write(key,value) 输出 MapTask 的中间处理结果,在相关的 collect(key,value) 方法中,会调用 Partitioner.getPartition(K2 key,V2 value,int numPartitions) 方法获得输出的 key/value 对应的分区号(分区号可以认为对应着一个要执行 ReduceTask 的节点),然后将 <key,value,partition> 暂时保存在内存中的 MapOutputBuffe 内部的环形数据缓冲区,该缓冲区的默认大小是 100MB,可以通过参数 io.sort.mb 来调整其大小。
当缓冲区中的数据使用率达到一定阀值后,触发一次 Spill 操作,将环形缓冲区中的部分数据写到磁盘上,生成一个临时的 Linux 本地数据的 spill 文件;然后在缓冲区的使用率再次达到阀值后,再次生成一个 spill 文件。直到数据处理完毕,在磁盘上会生成很多的临时文件。
MapOutputBuffer 内部存数的数据采用了两个索引结构,涉及三个环形内存缓冲区。下来看一下两级索引结构:
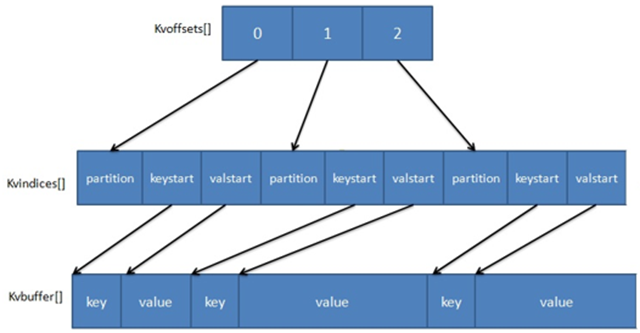
三个环形缓冲区:
- kvoffsets 缓冲区,也叫偏移量索引数组,用于保存 key/value 信息在位置索引 kvindices 中的偏移量。当 kvoffsets 的使用率超过 sort.spill.percent(默认为 80%)后,便会触发一次 SpillThread 线程的“溢写”操作,也就是开始一次 Spill 阶段的操作。
- kvindices 缓冲区,也叫位置索引数组,用于保存 key/value 在数据缓冲区 kvbuffer 中的起始位置。
- kvbuffer 即数据缓冲区,用于保存实际的 key/value 的值。默认情况下该缓冲区最多可以使用 sort.mb 的 95%,当 kvbuffer 使用率超过 io.sort.spill.percent(默认为 80%)后,便会出发一次 SpillThread 线程的“溢写”操作,也就是开始一次 Spill 阶段的操作。
2、Sort 阶段
先把 Kvbuffer 中的数据按照 partition 值和 key 两个关键字升序排序,移动的只是索引数据,排序结果是 Kvmeta 中数据按照 partition 为单位聚集在一起,同一 partition 内的按照 key 有序。
3、Spill 阶段
当缓冲区的使用率达到一定阀值后,触发一次“溢写”操作,将环形缓冲区中的部分数据写到 Linux 的本地磁盘。需要特别注意的是,在将数据写磁盘之前,先要对要写磁盘的数据进行一次排序操作,先按 <key,value,partition> 中的 partition 分区号排序,然后再按 key 排序,再必要的时候,比如说配置了 Combiner 并且当前系统的负载不是很高的情况下会将有相同 partition 分区号和 key 的数据做聚合操作,还有如果设置而对中间数据做压缩的配置则还会做压缩操作。
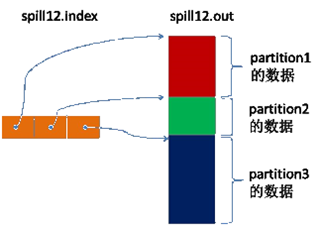
Spill 线程为这次 Spill 过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out”的文件。Spill 线程根据排过序的 Kvmeta 挨个 partition 的把 <key,value> 数据吐到这个文件中,一个 partition 对应的数据吐完之后顺序地吐下个 partition,直到把所有的 partition 遍历完。一个 partition 在文件中对应的数据也叫段(segment)。
所有的 partition 对应的数据都放在这个文件里,虽然是顺序存放的,但是怎么直接知道某个 partition 在这个文件中存放的起始位置呢?强大的索引又出场了。有一个三元组记录某个 partition 对应的数据在这个文件中的索引:起始位置、原始数据长度、压缩之后的数据长度,一个 partition 对应一个三元组。然后把这些索引信息存放在内存中,如果内存中放不下了,后续的索引信息就需要写到磁盘文件中了:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out.index”的文件,文件中不光存储了索引数据,还存储了 crc32 的校验数据。(spill12.out.index 不一定在磁盘上创建,如果内存(默认 1M 空间)中能放得下就放在内存中,即使在磁盘上创建了,和 spill12.out 文件也不一定在同一个目录下。)
每一次 Spill 过程就会最少生成一个 out 文件,有时还会生成 index 文件,Spill 的次数也烙印在文件名中。索引文件和数据文件的对应关系如下图所示:
话分两端,在 Spill 线程如火如荼的进行 SortAndSpill 工作的同时,Map 任务不会因此而停歇,而是一无既往地进行着数据输出。Map 还是把数据写到 kvbuffer 中,那问题就来了:<key,value> 只顾着闷头按照 bufindex 指针向上增长,kvmeta 只顾着按照 Kvindex 向下增长,是保持指针起始位置不变继续跑呢,还是另谋它路?如果保持指针起始位置不变,很快 bufindex 和 Kvindex 就碰头了,碰头之后再重新开始或者移动内存都比较麻烦,不可取。Map 取 kvbuffer 中剩余空间的中间位置,用这个位置设置为新的分界点,bufindex 指针移动到这个分界点,Kvindex 移动到这个分界点的 -16 位置,然后两者就可以和谐地按照自己既定的轨迹放置数据了,当 Spill 完成,空间腾出之后,不需要做任何改动继续前进。分界点的转换如下图所示:
Map 任务总要把输出的数据写到磁盘上,即使输出数据量很小在内存中全部能装得下,在最后也会把数据刷到磁盘上。
4、Combine 阶段待MapTask任务的所有数据都处理完后,会对任务产生的所有中间数据文件做一次合并操作,以确保一个MapTask最终只生成一个中间数据文件。
5、Copy阶段。
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。每个节点都会启动一个常驻的HTTP server,其中一项服务就是响应Reduce拖取Map数据。当有MapOutput的HTTP请求过来的时候,HTTP server就读取相应的Map输出文件中对应这个Reduce部分的数据通过网络流输出给Reduce。
Reduce任务拖取某个Map对应的数据,如果在内存中能放得下这次数据的话就直接把数据写到内存中。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中。
如果在内存中不能放得下这个Map的数据的话,直接把Map数据写到磁盘上,在本地目录创建一个文件,从HTTP流中读取数据然后写到磁盘,使用的缓存区大小是64K。拖一个Map数据过来就会创建一个文件,当文件数量达到一定阈值时,开始启动磁盘文件merge,把这些文件合并输出到一个文件。
有些Map的数据较小是可以放在内存中的,有些Map的数据较大需要放在磁盘上,这样最后Reduce任务拖过来的数据有些放在内存中了有些放在磁盘上,最后会对这些来一个全局合并。
默认情况下,当整个MapReduce作业的所有已执行完成的MapTask任务数超过MapTask总数的5%后,JobTracker便会开始调度执行ReduceTask任务。然后ReduceTask任务默认启动mapred.reduce.parallel.copies(默认为5)个MapOutputCopier线程到已完成的MapTask任务节点上分别copy一份属于自己的数据。 这些copy的数据会首先保存的内存缓冲区中,当内冲缓冲区的使用率达到一定阀值后,则写到磁盘上。
6、Merge阶段
在远程copy数据的同时,ReduceTask在后台启动了两个后台线程对内存和磁盘上的数据文件做合并操作,以防止内存使用过多或磁盘生的文件过多。
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。最后把这些文件进行合并的merge过程闪亮登场。
Merge过程怎么知道产生的Spill文件都在哪了呢?从所有的本地目录上扫描得到产生的Spill文件,然后把路径存储在一个数组里。Merge过程又怎么知道Spill的索引信息呢?没错,也是从所有的本地目录上扫描得到Index文件,然后把索引信息存储在一个列表里。到这里,又遇到了一个值得纳闷的地方。在之前Spill过程中的时候为什么不直接把这些信息存储在内存中呢,何必又多了这步扫描的操作?特别是Spill的索引数据,之前当内存超限之后就把数据写到磁盘,现在又要从磁盘把这些数据读出来,还是需要装到更多的内存中。之所以多此一举,是因为这时kvbuffer这个内存大户已经不再使用可以回收,有内存空间来装这些数据了。(对于内存空间较大的土豪来说,用内存来省却这两个io步骤还是值得考虑的。)
然后为merge过程创建一个叫file.out的文件和一个叫file.out.Index的文件用来存储最终的输出和索引。
一个partition一个partition的进行合并输出。对于某个partition来说,从索引列表中查询这个partition对应的所有索引信息,每个对应一个段插入到段列表中。也就是这个partition对应一个段列表,记录所有的Spill文件中对应的这个partition那段数据的文件名、起始位置、长度等等。
然后对这个partition对应的所有的segment进行合并,目标是合并成一个segment。当这个partition对应很多个segment时,会分批地进行合并:先从segment列表中把第一批取出来,以key为关键字放置成最小堆,然后从最小堆中每次取出最小的<key,value>输出到一个临时文件中,这样就把这一批段合并成一个临时的段,把它加回到segment列表中;再从segment列表中把第二批取出来合并输出到一个临时segment,把其加入到列表中;这样往复执行,直到剩下的段是一批,输出到最终的文件中。
最终的索引数据仍然输出到Index文件中。
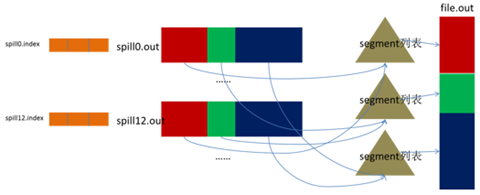
Map端的Shuffle过程到此结束。
6、MergeSort阶段
在合并的同时,也会做排序操作。由于各个MapTask已经实现对数据做过局部排序,故此ReduceTask只需要做一次归并排序即可保证copy数据的整体有序性。执行完合并与排序操作后,ReduceTask会将数据交给reduce()方法处理。
这里使用的Merge和Map端使用的Merge过程一样。Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。
Reduce端的Shuffle过程至此结束。
HDFS
HDFS是分布式计算的存储基石,Hadoop的分布式文件系统和其他分布式文件系统有很多类似的特质。分布式文件系统基本的几个特点:
- 对于整个集群有单一的命名空间。
- 数据一致性。适合一次写入多次读取的模型,客户端在文件没有被成功创建之前无法看到文件存在。
- 文件会被分割成多个文件块,每个文件块被分配存储到数据节点上,而且根据配置会由复制文件块来保证数据的安全性。

上图中展现了整个HDFS三个重要角色:NameNode、DataNode和Client。NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。这里通过三个操作来说明他们之间的交互关系。
文件写入:
- Client向NameNode发起文件写入的请求。
- NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
- Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取:
- Client向NameNode发起文件读取的请求。
- NameNode返回文件存储的DataNode的信息。
- Client读取文件信息。
文件Block复制:
- NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效。
- 通知DataNode相互复制Block。
- DataNode开始直接相互复制。
最后再说一下HDFS的几个设计特点(对于框架设计值得借鉴):
- Block的放置:默认不配置。一个Block会有三份备份,一份放在NameNode指定的DataNode,另一份放在与指定DataNode非同一Rack上的DataNode,最后一份放在与指定DataNode同一Rack上的DataNode上。备份无非就是为了数据安全,考虑同一Rack的失败情况以及不同Rack之间数据拷贝性能问题就采用这种配置方式。
- 心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
- 数据交验:采用 CRC32 作数据交验。在文件 Block 写入的时候除了写入数据还会写入交验信息,在读取的时候需要交验后再读入。
- NameNode 是单点:如果失败的话,任务处理信息将会纪录在本地文件系统和远端的文件系统中。
- 数据管道性的写入:当客户端要写入文件到 DataNode 上,首先客户端读取一个 Block 然后写到第一个 DataNode 上,然后由第一个 DataNode 传递到备份的 DataNode 上,一直到所有需要写入这个 Block 的 NataNode 都成功写入,客户端才会继续开始写下一个 Block。
- 安全模式:在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个 DataNode 上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
数据复制(场景为 DataNode 失败、需要平衡 DataNode 的存储利用率和需要平衡 DataNode 数据交互压力等情况):这里先说一下,使用 HDFS 的 balancer 命令,可以配置一个 Threshold 来平衡每一个 DataNode 磁盘利用率。例如设置了 Threshold 为 10%,那么执行 balancer 命令的时候,首先统计所有 DataNode 的磁盘利用率的均值,然后判断如果某一个 DataNode 的磁盘利用率超过这个均值 Threshold 以上,那么将会把这个 DataNode 的 block 转移到磁盘利用率低的 DataNode,这对于新节点的加入来说十分有用。
Hadoop 2.0
Hadoop 是 Apache 的一个分布式系统基础架构,可以为海量数据提供存储和计算。Hadoop 2.0 即第二代 Hadoop 系统,其框架最核心的设计是 HDFS、MapReduce 和 YARN。其中,HDFS 为海量数据提供存储,MapReduce 用于分布式计算,YARN 用于进行资源管理。
Hadoop 1.0 和 Hadoop 2.0 的结构对比:
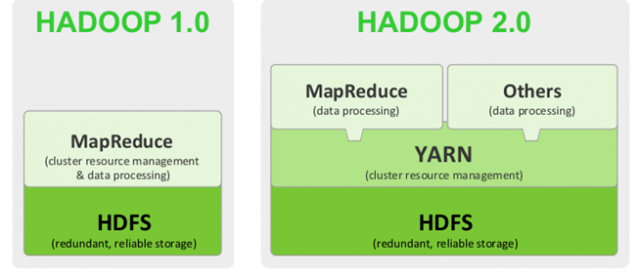
Hadoop 2.0 的主要改进有:
- 通过 YARN 实现资源的调度与管理,从而使 Hadoop 2.0 可以运行更多种类的计算框架,如 Spark 等。
- 实现了 NameNode 的 HA 方案,即同时有 2 个 NameNode(一个 Active 另一个 Standby),如果 Active NameNode 挂掉的话,另一个 NameNode 会转入 Active 状态提供服务,保证了整个集群的高可用。
- 实现了 HDFS federation,由于元数据放在 NameNode 的内存当中,内存限制了整个集群的规模,通过 HDFS federation 使多个 NameNode 组成一个联邦共同管理 DataNode,这样就可以扩大集群规模。
- Hadoop RPC 序列化扩展性好,通过将数据类型模块从 RPC 中独立出来,成为一个独立的可插拔模块。
YARN 基本架构
YARN 是 Hadoop 2.0 的资源管理器。它是一个通用的资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN 的基本设计思想是将 Hadoop 1.0 中的 JobTracker 拆分成了两个独立的服务:一个全局的资源管理器 ResourceManager 和每个应用程序特有的 ApplicationMaster。其中 ResourceManager 负责整个系统的资源管理和分配,而 ApplicationMaster 负责单个应用程序的管理,其基本架构如下图所示:
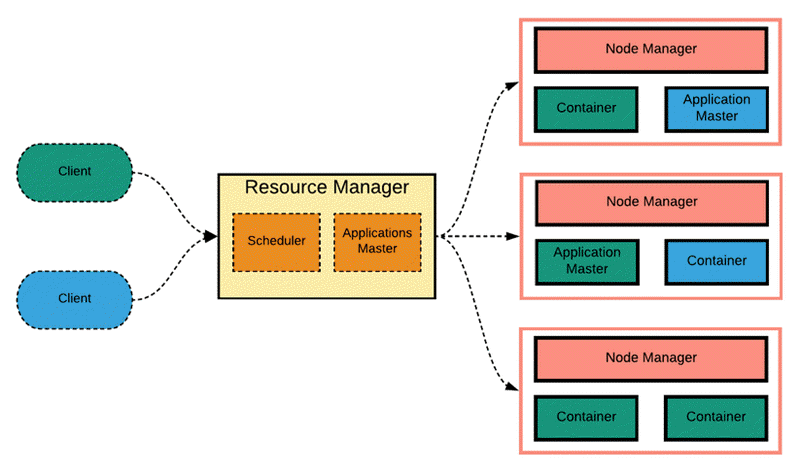
YARN 总体上仍然是 Master/Slave 结构。在整个资源管理框架中,ResourceManager 为 Master,NodeManager 为 Slave,并通过 HA 方案实现了 ResourceManager 的高可用。ResourceManager 负责对各个 NodeManager 上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的 ApplicationMaster,它负责向 ResourceManager 申请资源,并要求 NodeManger 启动可以占用一定资源的任务。由于不同的 ApplicationMaster 被分布到不同的节点上,因此它们之间不会相互影响。
- ResourceManager:它是一个全局的资源管理器,负责整个系统的资源管理和分配,主要由调度器和应用程序管理器两个组件构成。
- 调度器:根据容量、队列等限制条件,将系统中的资源分配给各个正在运行的应用程序。调度器仅根据应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念”资源容器”(简称 Container)表示,Container 是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。
- 应用程序管理器:负责管理整个系统中所有的应用程序,包括应用程序提交、与调度器协商资源以启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重新启动它等。
- ApplicationMaster:用户提交的每个应用程序均包含 1 个 ApplicationMaster,主要功能包括与 ResourceManager 调度器协商以获取资源、将得到的任务进一步分配给内部的任务、与 NodeManager 通信以启动/停止任务、监控所有任务运行状态并在任务运行失败时重新为任务申请资源以重启任务等。
- NodeManager:它是每个节点上的资源和任务管理器,它不仅定时向 ResourceManager 汇报本节点上的资源使用情况和各个 Container 的运行状态,还接收并处理来自 ApplicationMaster 的 Container 启动/停止等各种请求。
- Container:它是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当 ApplicationMaster 向 ResourceManager 申请资源时,返回的资源便是用 Container 表示的。YARN 会为每个任务分配一个 Container,且该任务只能使用该 Container 中描述的资源。
YARN 工作流程
当用户给 Yarn 提交了一个应用程序后,Yarn 的主要工作流程如下图:
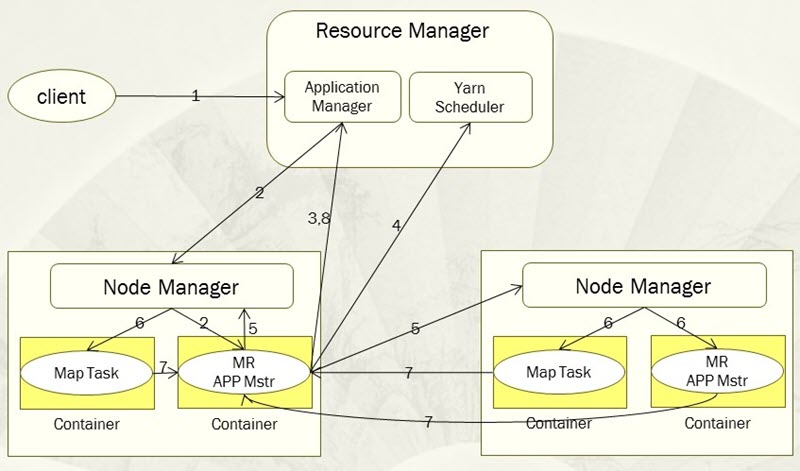
- 步骤 1,用户向 Yarn 提交应用程序,其中包括用户程序、相关文件、启动 ApplicationMaster 命令、ApplicationMaster 程序等。
- 步骤 2,ResourceManager 为该应用程序分配第一个 Container,并且与 Container 所在的 NodeManager 通信,并且要求该 NodeManager 在这个 Container 中启动应用程序对应的 ApplicationMaster。
- 步骤 3,ApplicationMaster 首先会向 ResourceManager 注册,这样用户才可以直接通过 ResourceManager 查看到应用程序的运行状态,然后它为准备为该应用程序的各个任务申请资源,并监控它们的运行状态直到运行结束,即重复后面 4~7 步骤。
- 步骤 4,ApplicationMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源。
- 步骤 5,一旦 ApplicationMaster 申请到资源后,便会与申请到的 Container 所对应的 NodeManager 进行通信,并且要求它在该 Container 中启动任务。
- 步骤 6,任务启动。NodeManager 为要启动的任务配置好运行环境,包括环境变量、JAR 包、二进制程序等,并且将启动命令写在一个脚本里,通过该脚本运行任务。
- 步骤8,应用程序运行完毕后,其对应的 ApplicationMaster 会向 ResourceManager 通信,要求注销和关闭自己。
步骤7,各个任务通过 RPC 协议向其对应的 ApplicationMaster 汇报自己的运行状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务运行失败时重启任务。
这个需要注意的是在整个工作流程当中,ResourceManager 和 NodeManager 都是通过心跳保持联系的,NodeManager 会通过心跳信息向 ResourceManager 汇报自己所在节点的资源使用情况。