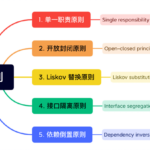
SOLID原则是一组面向对象编程中的设计原则,旨在提高软件设计的可维护性、灵活性和扩展性。这些原则由罗伯特·C·马丁(Robert C. Martin)提出,是软件开发中广泛认可的最佳实践。SOLID是五个原则的首字母缩写,每个…
JSON在开发场景的应用 JSON(JavaScript Object Notation)在开发中因其轻量级、易读、灵活的特性,已成为处理结构化或半结构化数据的首选格式。 前后端数据交互 场景:客户端(Web/App)与服务器之间的…
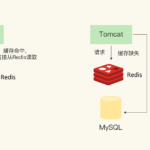
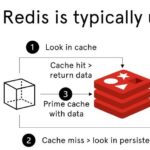
Redis作为缓存使用时,支持多种缓存策略,主要用于在内存不足时淘汰数据。 以下是Redis的主要缓存策略及其应用场景和配置方法: Redis内置数据淘汰策略 通过 maxmemory-policy 配置项指定淘汰策略(需设置 maxme…
FastAPI中实现缓存可以提高应用的性能,尤其是在处理重复请求的时候,减少数据库的压力,加快响应速度。 缓存后端 根据应用需求选择合适的缓存后端: 内存缓存(InMemory):适用于单进程开发环境,简单快速,…
在设计 FastAPI 项目结构时,需要根据项目规模(小型/中型/大型)、项目类型(纯 API/全栈应用/微服务)和团队协作需求灵活调整。 以下是针对不同场景的实践指南和示例: 核心设计原则 模块化:按功能拆分代码…

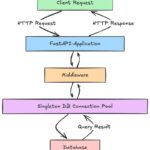
在 FastAPI 中,连接数据库通常使用SQLAlchemy(适用于关系型数据库)或Tortoise-ORM(异步 ORM)。以下是基于 SQLAlchemy 和 Tortoise-ORM 的常见方法: FastAPI 与 SQLAlchemy 的集成 FastAPI 与 SQLAlchemy 集…

常见权限管理模式 权限管理是系统安全的核心组件,不同场景需适配不同模式。以下是7种常见方案及其适用场景、实现示例和选型指南: RBAC(基于角色的访问控制) 原理:用户关联角色→角色关联权限 层级结构:用…
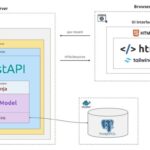
FastAPI 完全可以接入模板引擎来开发传统网站!虽然 FastAPI 以构建高性能 API 著称,但它基于 Starlette 框架,天然支持模板渲染和静态文件托管。 模板引擎选型 引擎 特点 安装命令 Jinja2 语法简洁,广泛…
OAuth2与JWT OAuth2和JWT是两种常用于身份验证与授权的技术,但它们的核心目标和应用场景不同。 本质区别 特性 OAuth2 JWT 定位 授权框架(定义资源访问的流程) 令牌格式(安全传输信息的标准) 核心目标…

在 FastAPI 中接入中间件(Middleware)非常简单,因为 FastAPI 基于 Starlette 框架,可以直接使用 Starlette 的中间件系统。 中间件基础概念 中间件是 FastAPI 中用于拦截HTTP 请求和响应的组件,它在请求到达…